 |
Komprese bitonálního obrazu: současné trendy |
| Adolf Knoll, Národní knihovna ČR, Praha |
| Vývoj v oblasti komprese bitonálního obrazu zajią»uje vyąąí stupně komprese neľ pouľivané standardy.
Na základě řady testů budou představena nová schémata a metody vč. perspektiv jejich vyuľití. |
Compression of bi-level images
Compressor performance report
Adolf Knoll, National Library of the Czech Republic, Prague
In most cases, document delivery
services as well as various digitization activities are based on black-and-white
images. These digital images can provide access to most important textual
and partly also graphical information contained in newspapers, journals,
and other types of printed documents and modern records. This is the information,
which is not available in electronic form, because of the fact that it
was printed on paper, but its digitization can contribute to its wider
dissemination and also more manageable archiving.
Let us imagine a page from an old journal: its original size was ca. 83
x 91,5 cm, it was scanned from microfilm at 150 dpi. Thus, we need for
it 4901 x 5410 = 26514410 pixels that means for true colour image - in
which each pixel consists of 24 bits = 3 bytes - ca. 79,5 MB. If we take
in consideration that we would like to provide Internet access to such
an image or to image of pages of this journal, it would be very difficult
to transfer approximately 80 MB of data for each page. For much Internet
access in slow networks it would be even impossible.
The old journals consisted mostly of black texts on white pages with scarce
drawings and later also with photographs. For most of them the black-and-white
image (bi-level or bi-tonal image) would be good enough to offer appropriate
access to the information contained.
The bi-level image means that for each pixel (picture element) from the
scanned image we do not need three bytes as in the true colour image (over
16.7 million colours), but only one bit that is 1/24 part of the pixel
size from the true colour image. The one-bit pixel can express only black
or white colours, nothing more, but if the number of pixels per unit of
length (called resolution) is sufficiently higher, such a solution can
bring satisfactory results. In case of our above-mentioned page, the size
of the corresponding bi-level image will be ca. 3.314 MB. However, even
such a file is pretty large for reasonable transfer; therefore, techniques
must be found to compress it down.
Bi-level images are a very classical domain of interest of fax industry,
because facsimile machines need efficient standards for speeding up transmission
of documents. In 1980, an international standard called Group 3 was recommended
by a study group of the International Telegraph and Telephone Consultative
Committee (CCITT) for this purpose. This standard implemented a simple
compression scheme that enabled a substantial lossless reduction of transmitted
bi-level files. If applied to our file, the result will be 477 KB of data
that is more manageable than the uncompressed form. Most facsimile machines
of today use still this compression scheme for document transfer.
However, further work on this CCITT Group 3 standard went on, and in 1984
an improved compression scheme called Group 4 was recommended as an international
standard. If not very much used in daily faxing, the standard found its
way in digital imaging as well as the previous CCITT G3 standard. This
happened thanks to the fact that both of them were incorporated in the
TIFF 4.0 format.
In the case of our page from the old journal the G4 scheme is able to compress
the file down onto 192 KB without losses of information face to the uncompressed
file. This result is not bad compared to 3314 KB of the uncompressed file;
therefore, the G4 scheme implemented in TIFF is also frequently used as
the output and access format for most scanned documents. It was also recommended
for the textual documents digitized within the UNESCO Memory of the World
programme.
Nevertheless, the search of better and better compression schemes for the
bi-level image went on. In 1993, the Joint Bi-level Image Experts Group
(JBIG) produced a new bi-level image coding standard (ISO/IEC 11544) known
as JBIG and called nowadays also JBIG1. However, this compression scheme,
which outperformed the G4 standard, was not largely applied, because there
was no commonly used data format enabling the practical work with this
scheme.
Nowadays, it is expected that an improved JBIG2 compression scheme will
be adopted as an international ISO standard during the year 2000, because
it has already got the Final Draft ISO International Standard status. The
JBIG2 scheme will enable further lossless and even lossy compression of
the bi-level image.
There are several companies, which are experimenting now with implementation
of JBIG2 into usable data formats, for example, the Xerox Corp. and Image
Power Inc. The latter company has enabled it in its recent product called
Power Compressor1 as the file type JB2.
Other companies are following similar principles to elaborate efficient
compression schemes for the bi-level image. The AT&T laboratories implemented
their variation proposal for JBIG2 into their new DJVU format as a JB2
sub-component for encoding that part of the image that is considered to
be foreground. The German LuraTech Comp. designed another bi-level encoding
scheme that was implemented in their new LDF format for the same reason
as it was done with JB2 by the AT&T laboratories. This scheme has no
specific name; therefore, it will be referred to as LDF bi-tonal encoder.
Finally, there is also a Lightning Strike solution developed by Infinop,
Inc.
All these schemes - and possibly also other ones - have in common further
tightening of compression. Some of them are well elaborated and it is possible
to test them, while the authoring or viewing tools for other ones are not
available. Usually, the new schemes offer both lossless and lossy compression.
Thus, we achieved the best results for our journal page through application
of the DJVU JB2 encoder: 154 KB for the lossless option and 109 KB for
the so-called aggressive lossy option whose quality was, however, fully
acceptable. Compared with 192 KB of CCITT G4 this is a very good result
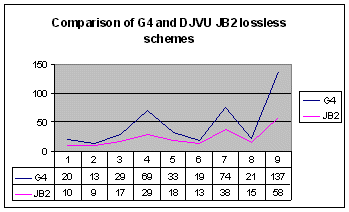
as we can see below on the Fig. no. 1.

Fig. no. 1 – Comparison of file
sizes after compression by various schemes (old journal)
Of course, even more interesting would be to compare the 109 KB achieved
by JB2 in DJVU with 79,5 MB for the true-colour image as shown in Fig.
no. 2. Thus, it is quite evident that the bi-level image has its good future
and that the search of better compression schemes - the lossy ones included
- can contribute to easier, cheaper, and faster access to scanned information.
The advantages of such solutions have been shown on a rather large file
produced through digitization of an old 19th century journal. Keeping in
view the processing techniques to enable such a compression ratio, it becomes
evident that compression of more recent texts and better-quality documents
should give far better results.

Fig. no. 2 – Comparison of extreme
file sizes (old journal)
As we are engaged in a digitization programme related to old newspapers
and journals, it was rather tentative for us to get better orientation
in this problem and to test available schemes and tools.
Tools
We were able to find the following authoring
tools, which enabled us to try new bi-level compression schemes:
-
Power Compressor 1.04 by Image Power,
Inc., for the company's JBIG2 variation called JB2;
-
DjVu™ Shop, Version 2.0 (Beta 2) by
AT&T Corporation, for the company's variation of JBIG2 called also
JB2;
-
LuraDocument® Photoshop Plug-In,
Version 2.5.00.51, by LuraTech GmBH, for the company's bi-tonal encoder
implemented as an option in the LuraDocument (LDF) format.
The CCITT G3 and G4 schemes in TIFF were processed in the Graphic Workshop
Professional, Version 2.0a, Patch 6.
The Power Compressor enables to take directly a black-and-white TIFF file
and to let it save as a JB2 format. The resulted JB2 file (e.g., myfile.jb2)
can be viewed only in the Power Compressor in spite of the fact that the
Power Compressor Netscape plug-in foresees the JB2 extension to be processed.
However, it does not work. Nevertheless, it was not difficult to process
a series of reasonably large and standardized files to have the necessary
compressed output.
The DJVU and LDF formats have, however, another philosophy. They were designed
to enable the so-called mixed raster content encoding through combining
of different schemes for different image layers. Both of them split the
image between foreground and background layers, while the foreground layers
are encoded in bi-level schemes: in DJVU it is a JB2 scheme and in LDF
there is an option between CCITT G4 and the LDF own bi-tonal encoder. The
foreground level is normally combined with background layers encoded by
a modern wavelet compression technique called IW44 for DJVU and LWF for
LDF formats. One of these background layers is in fact applicable as a
background image for the bi-level foreground image, while the other layers
(one in LDF and four in IW44) are used for images.
The foreground layer concerns the information that is considered to be
the text as the encoding scheme is based on repeatability of characters
or pixel groups on the page image and the sophisticated encoding of the
found redundancy.
The problem was, whether the above mentioned authoring tools would enable
solely encoding of the bi-level image without application of wavelets for
background. The DjVu™ Shop enables it directly, because it offers the option
to process any image as a black-and-white document. In this way, the DJVU
format contains only the JB2 component, while the IW44 components are switched
off. The JB2 bi-level encoding can be set as lossless, lossy, or aggressive.
The file extension even in this case remains to be DJVU (e.g., myfile.djvu).
It is accessible in web browsers (both Netscape and Internet Explorer)
with the help of a user-friendly plug-in.
In the case of the LDF bi-tonal encoder, however, the situation is more
complicated as LDF does not enable the direct encoding of bi-level source
files. The solution is to increase the number of colours up to 16 million
and to set the option in the dialogue menu that everything should be encoded
and that this everything should be considered to be text. If so, the LDF
Adobe Photoshop Plug-In applies really only its bi-level encoder, but the
manipulation with images with increased number of colours requires much
computing.
If the user-friendliness of encoding software combined with its speed and
computation efficiency is evaluated, the winner is the DjVu™ Shop. It has
never happened - even in case of very large files - larger than that mentioned
beforehand - that the encoder or the computer have frozen during encoding.
However, this was the case of the Power Compressor when processing large
files, while the LDF Plug-In was rather stable, but it had to manage very
large files by default that caused also some problems.
We wanted to compare our results with
similar tests - if any - made by others so that we could be sure that in
our tests we would work under the same or at least very similar conditions.
If so, this could give us a good starting point for tests and comparison
especially of the DJVU and LDF bi-level encoders with known confirmed values.
We were happy to find interesting test results of bi-level compression
schemes on the web page of the Image Power, Inc.; luckily also with nine
tested images2. The images were available in
GIF format. We downloaded them and we converted them into bi-level uncompressed
TIFF images that were designed to be considered as our source test files.
The Image Power results contained - as a point of reference - also measurements
for CCITT G4 and the company's JBIG2 schemes. We repeated the tests for these
two schemes on the supposedly identical images of which - after their downloading
and conversion - we were not sure enough how much they were identical to
those on which the Image Power, Inc., performed the tests.
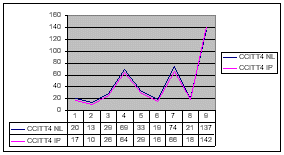 As
to the tests of the CCITT G4 compression scheme, we obtained quite comparable
results, while the slight differences might be caused by the fact that
our tests ran on slightly - but not critically - modified images. If looking
at the graph both CCITT G4 (NL stays for the National Library and IP for
Image Power Inc.) curves have similar developments from document to document.
As
to the tests of the CCITT G4 compression scheme, we obtained quite comparable
results, while the slight differences might be caused by the fact that
our tests ran on slightly - but not critically - modified images. If looking
at the graph both CCITT G4 (NL stays for the National Library and IP for
Image Power Inc.) curves have similar developments from document to document.
This was not, however the case of JBIG2 compression performed in the Image
Power Compressor. Here some results were similar, while the other ones
looked differently. This fact might be caused by different pre-processing
techniques used by the company in their tests opposite to the technique
implemented in their Power Compressor for JBIG2. In our further analyses
on other more complicated documents, it was evident that the JB2 format
built in the Power Compressor gave unsatisfactory results that will be
discussed later.
Nevertheless the CCITT G4 results - and even the JBIG2 results - confirmed
the fact that the downloaded samples are appropriate for our tests. In
fact 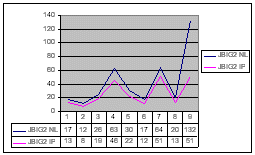 the
only radical difference in JBIG2 compression is observable at the results
concerning the Sample no. 9.
the
only radical difference in JBIG2 compression is observable at the results
concerning the Sample no. 9.
If analysing this sample, we can
see that it contains also extremely small (fine) characters in sets of
10, 8, 6, 4, 3, and 2 points. It may be that the quality of pre-processing
routines of the encoder used by the company was better than the quality
of pre-processing routines used by the encoder built in the available software.
As we discovered later, the JBIG2 compression built in the Power Compressor
was lossy and gave poor results on documents with small characters.
The differences in results seemed to be explained also by the fact that
in case of their another series of tests [3] the company
stated that they had used other tools for simulating JBIG coding scheme.
Furthermore, when we printed out the sample page, we could not discern
the smaller sets of characters. It is highly probable that the available
encoder was not able to work with them separately; therefore, it encoded
bitmaps of these groups of pixels as a whole and the file remained relatively
large. This fact seems to be proved also by the fact that at this sample
the compression scheme built in the PNG format - good for images - was
much more successful than the lossless CCITT G4 and G3 schemes and the
result of JBIG2 obtained through the Power Compressor.
This result was very close to the result of classical lossless schemes:
132 KB for JBIG2 compared with 137 KB for CCITT G4 and 145 KB for CCITT
G3, while the PNG output was only 77 KB. Also very similar results for
both CCITT G3 and G4 confirm this idea, because normally G4 is far better
than G3. Maybe this was also the cause of the fact that in another series
of tests [3], the company excluded this sample from tested materials.
The obtained results warned us to be careful when comparing our data with
the published results of the company: if doing this, small differences
in compared data should be disregarded, while more substantial ones should
be analysed. However, our aim was not so much to compare our measurements
with other measurements even on the same data; we wanted to have standard
monochrome images with different graphic objects (characters, graphs, halftones)
to perform our own tests on available bi-level compression schemes.
In conclusion, we found the downloaded samples good for performing our
own tests. The appropriateness of our choice of was also strengthened by
the fact that it was a set of documents chosen originally by CCITT as reference
test documents.
The company's tests contained also values obtained through implementation
of special lossy pre-procession techniques3
called Combined Symbol Matching (CSM) and Modified Combined Symbol Matching
(MCSM) that gave very interesting results. This fact promised to be interesting
because of availability of lossy options also in the DJVU bi-level compression
scheme.
Test results
We tested the following formats: TIFF
CCITT G3, TIFF CCITT G4, JBIG2 of the Image Power Compressor, LDF bi-tonal
encoder, DJVU JB2 separately for lossless, lossy, and aggressive lossy
compression. For comparison the PNG format was applied, too.
The results are shown on the enclosed graph below; they contain also partial
results discussed separately.
General observations
CCITT G3 and CCITT G4
The CCITT G3 and G4 schemes gave expected
results: the G4 scheme was better at all the nine samples. It showed the
best performance over G3 especially in case of drawings (samples nos. 2,
3, and 6), while in case of texts it outperformed G3 approximately twice
(especially samples nos. 1, 4, and 7). It was even better more than twice
at the sample no. 5, which consists of mixed contents: text and drawings.
The difference as to sample no. 10 is not so important due to complicated
structure of objects.
It is also interesting to see that G3 was outperformed by PNG in all the
tested cases, while G4 only in case of the sample no. 10, which contains
halftones and very small characters.
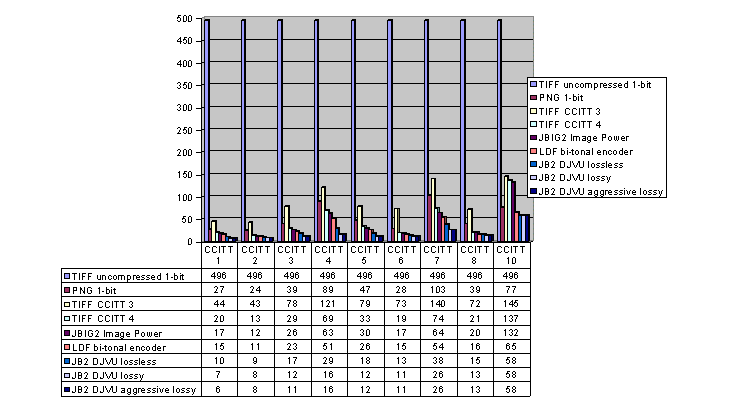
Image Power Compressor JBIG2
This scheme was slightly better than
CCITT G3 and G4, but the difference face to G4 was not so important to
follow this line. Furthermore, additional tests showed that this implementation
of JBIG2 is lossy and that it encounters problems with more complicated
documents - G4 is lossless.
LDF bi-tonal encoder
The behaviour of this encoder was not
bad, its performance was better at all the tested samples, and it was also
able to compress efficiently the sample no. 10 down to 65 KB (face to ca.
double size at JBIG2, CCITT G3 and 4). It was also better than PNG and
the quality of decompressed data was good as well.
The tests on other samples have
proved that it is a lossless scheme. The only inconvenience today is that
it LuraDocument Plug-In for Adobe Photoshop does not accept bi-tonal images
as source files. However, this may change in the near future and LDF will
be able to become an interesting challenge for handling bi-level images.
DJVU JB2
 |
JB2 is a component part of the DjVu
format. The available software (see above) accepts bi-tonal source files
and it activates in this case only JB2. It is possible to the resolution
of the resulting image and the character of compression. Both of these
parameters can influence the size of the compressed file.
We accepted 300 dpi resolution option,
which is the default value. We compressed the source files separately under
the lossless, lossy, and aggressive options. The lossless compression outperformed
all the other previously discussed schemes.
In comparison with TIFF CCITT G4,
it was far better especially in case of texts (samples nos. 4 and 7) and
small text and halftones (last sample, here no. 9). |
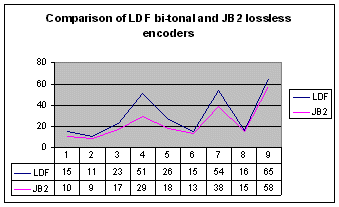 |
In comparison with the LDF bi-tonal
encoder, the JB2 lossless option was far better also in case of texts (samples
nos. 4 and 7). As to the last sample, the difference was not so relevant.
This facts seem to say that JB2 disposes of the best textual image pre-processing
and processing routines that consists namely in efficient handling of repeated
characters. It was successful to do it both in case of Latin and Chinese
characters; therefore, it can be said more generally that the quality consists
in handling individual pixel blocks. In fact, also the performance of the
LDF bi-tonal encoder contained some improvement of this routine face to
CCITT G3 and G4 schemes. The results obtained in case of the last sample
(here no. 9) prove that the LDF and JB2 encoders have brought significant
progresses in handling especially bi-level halftones. The quality of the
lossless compression of the DJVU JB2 encoder (a variation to JBIG2) is
underlined especially by good and freely available authoring software as
well as various other commercial tools. DjVu is also able to handle multipage
documents. This quality will be implemented in the version no. 3 of the
DjVu™ Shop. The browser plug-in enables Netscape and Internet Explorer
users to access and manipulate the djvu files on Internet. |
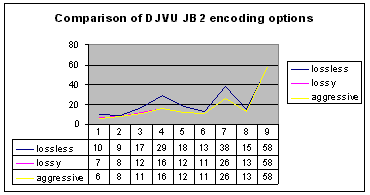 |
Further investigation concerned
lossy encoding schemes of the DJVU JB2. As it is evident from the nearby
graph, the lossy and aggressive compression options outperformed the lossless
encoding within the same format namely in case of textual samples nos.
4 and 7. This signalizes an improved handling of individual pixel blocks
represented by characters, indifferently of the fact, whether they are
Latin or Chinese. As the density of text diminishes, the prevalence of
both lossy schemes over the lossless one weakens or almost disappears,
while in case of halftones the results are identical (no. 9). It is also
interesting to observe that the differences between the lossy and aggressive
options are almost none or negligible. It seems that more complicated source
files (documents) will be needed to discover the character of losses in
individual options as well as the conditions under which the significance
of the aggressive option may become very important face to the lossy one.
More above, we stated significant differences between the size of files
encoded by these options in case of an old and large page from a 19th century
journal. |
Additional tests
We felt that some additional tests were
needed to establish especially the character of losses occurring during
lossy encoding. The CCITT test documents were unable to lead to such a
discovery; therefore, we decided to test some encoding schemes from above
on pages from old journals and newspapers, where the quality of the original
was poorer. We expected that thanks to a greater variety of occurring pixel
blocks and noise, some processing techniques would be visible after lossy
compression has taken place.
Pattern matching
The processing and pre-processing methods
are well described in the material entitled The Emerging JBIG2 Standard4.In
case of the so-called textual images (i.e. text represented by an image
file) the way towards lossy compression leads through the method called
pattern matching.
In this method individual pixel blocks (in texts in fact images of individual
characters) are analyzed in order to find out, which of them and where
occur more than once. The principle consists in the fact that each pixel
block of the same category is repeated many times on the same page as,
for example, the pixel block representing the character 'a' can have a
lot of occurrences on a page. If it is so, the bitmap of such a character
is encoded only once and it is added to a dictionary of representative
pixel blocks. If the encoder finds another pixel block matching the pixel
block, which is in the dictionary, this new pixel block is not encoded
again. Only its reference to the pixel block from the dictionary is marked
as well as the position within the page. Thus, the bitmap of a character
is encoded only once, while all its occurrences are given as references
to the representative block from the dictionary.
As on scanned textual pages there can be much noise and not all the characters
are imaged by the same number and arrangement of pixels, the encoder must
weigh, whether the match would be acceptable or not. If it is acceptable,
the pixel block is not encoded, it is only substituted by the pixel block
from the dictionary. If the match is not acceptable, the pixel block (character)
is encoded as a bitmap and added to the dictionary. Such a method is called
pattern
matching and substitution.
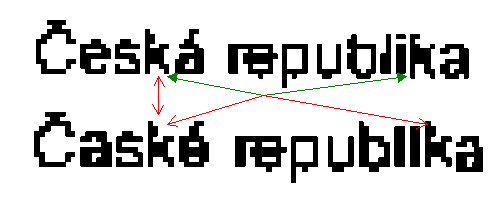 At
the neighbouring figure, the upper inscription is from an uncompressed
image, while the inscription below has been taken from an image compressed
by the Image Power Compressor into their JBIG2 (JB2) format. If we consider
the character 'k', we can see that the upper source image contains two
slightly different pixel blocks staying for this character. The applied
encoder found the second occurrence of this character as matching the first
one; therefore, it substituted it with the same pixel block so that the
two characters got the same appearance - as seen on the same image below
the source text.
At
the neighbouring figure, the upper inscription is from an uncompressed
image, while the inscription below has been taken from an image compressed
by the Image Power Compressor into their JBIG2 (JB2) format. If we consider
the character 'k', we can see that the upper source image contains two
slightly different pixel blocks staying for this character. The applied
encoder found the second occurrence of this character as matching the first
one; therefore, it substituted it with the same pixel block so that the
two characters got the same appearance - as seen on the same image below
the source text.
However, in case of other characters, there were many misinterpretations
in the compressed sample. Some of them did not affect the basic understanding
- for example, the last character 'a' - while the other ones changed it
as it was, for example, with the second character - that was 'e' - which
was matched to something that is rather understood as 'a'. Furthermore,
the character 'i' was changed into 'l'.
The source file was of poor quality in this case. It was taken from a scanned
instruction enclosed with a medicament. It was printed with very tiny characters
on normal paper, while the resolution was 300 dpi that was, however, quite
enough.
 It
was interesting in this case to find out, whether also other lossy schemes
did the same. As we can see on the following sample, the behaviour of the
DJVU JB2 aggressive scheme was better balanced and it did not affect the
correct understanding of the text. It is evident that the encoder used
a better method, probably that based on the similar principles as those
called soft pattern matching in which the pixel block from the dictionary
is used as a template to ensure more accuracy during interpretation of
characters (pixel blocks). It is a very robust method to small errors5.
This file built on this method was slightly larger than then previous file
built only on the basis of the pattern matching and substitution method.
It
was interesting in this case to find out, whether also other lossy schemes
did the same. As we can see on the following sample, the behaviour of the
DJVU JB2 aggressive scheme was better balanced and it did not affect the
correct understanding of the text. It is evident that the encoder used
a better method, probably that based on the similar principles as those
called soft pattern matching in which the pixel block from the dictionary
is used as a template to ensure more accuracy during interpretation of
characters (pixel blocks). It is a very robust method to small errors5.
This file built on this method was slightly larger than then previous file
built only on the basis of the pattern matching and substitution method.
However, its readability is quite good, while that of the previous file
is seriously affected.
It is evident that the methods called Combined Symbol Matching (CSM) and
Modified Combined Symbol Matching (MCSM) mentioned above [3] are based
on similar principles as well as methods used for compressing halftones.
Lossy pre-processing
In order to achieve high efficiency
of lossy encoding, several methods are used to prepare the source file
especially for improved application of the methods described above.
On the results obtained through lossy bi-level compression, some losses
can be observed that are obtained especially by flipping pixels. This flipping
of pixels is due namely to corrections resulted from the comparison of
pixel blocks with pixel blocks from the dictionary. It can prepare good
basis for substitution of characters or pixel blocks if the match is considered
sufficiently good.
On the comparison of the drawing of a model engine carburettor as obtained
from lossy, lossless, and aggressive compression in DJVU JB2, we can see
several differences caused by flipping pixels. 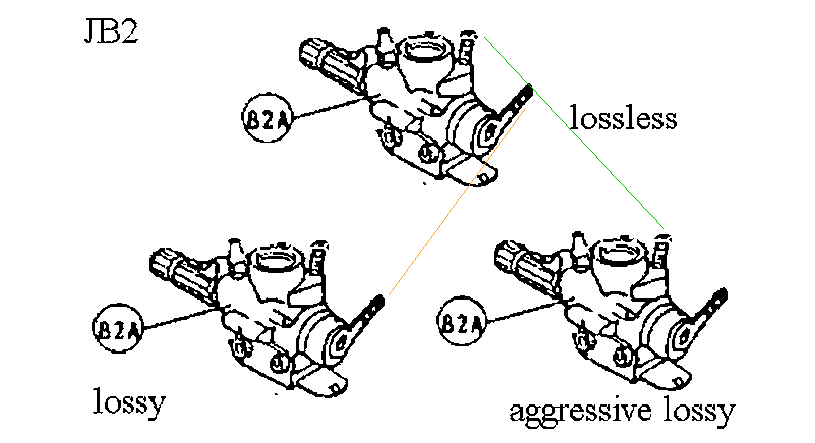
It is interesting to see also that there is no difference between the aggressive
and lossy methods, while there are losses made by these two methods face
to the lossless image.
If looking closer, we can distinguish clearly many changes caused by the
fact that individual pixels flipped: from black to white or from white
to black. This is done frequently in order to smooth edges of individual
pixel blocks.
 In
this case especially protruding singular black pixels are removed by flipping
to white or white pixels flip to black to fill in the edges. Both of these
situations can be seen at the nearby picture.
In
this case especially protruding singular black pixels are removed by flipping
to white or white pixels flip to black to fill in the edges. Both of these
situations can be seen at the nearby picture.
This smoothing procedure is even much more important in case of textual
documents, where it can contribute to better matching of encountered characters
with the representative character encoded as a bitmap in the dictionary.
Smoothing standardizes local edge shapes and it can increase the compression
ratio with about 10%.
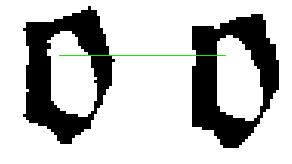 In
case of our tests with compression of scanned pages from the 19th century
journals and newspapers, this method proved itself to be very efficient,
because the scanned documents offered a larger variety of pixel blocks
than common modern printed texts. It was especially on such documents,
where differences between lossless, lossy, and aggressive encoding schemes
of DJVU JB2 grew substantially. When comparing a sequence of words [Fig.
A] from such an old printed text, we could find plenty of cases of smoothed
edges. This can be seen, among others, on the character 'o' taken from
a larger text of a 19th century journal.
In
case of our tests with compression of scanned pages from the 19th century
journals and newspapers, this method proved itself to be very efficient,
because the scanned documents offered a larger variety of pixel blocks
than common modern printed texts. It was especially on such documents,
where differences between lossless, lossy, and aggressive encoding schemes
of DJVU JB2 grew substantially. When comparing a sequence of words [Fig.
A] from such an old printed text, we could find plenty of cases of smoothed
edges. This can be seen, among others, on the character 'o' taken from
a larger text of a 19th century journal.
It seems that thanks to this smoothing method very good results are obtained
by the lossy DJVU JB2 option face to the lossless encoding: there were
123 KB obtained through lossy encoding compared with 154 KB obtained through
lossless encoding.
When we compared the pixel blocks (characters) obtained through lossy and
aggressive options, the differences between the shapes of character blocks
were none or very few. The same page compressed by the aggressive method,
however, had only 109 KB.
To find out, how the aggressive method works in comparison with the lossy
one, we took even a larger and more complicated page from a 19th century
newspaper. Again we observed very few smoothing differences between lossy
and aggressive methods. It seemed that almost everything had been already
done by the lossy option. However, it was discovered that the aggressive
option had a very strong de-noising feature that could be seen on the sequence
of words taken from a processed page of this newspaper [Fig. B]. The aggressive
method removed noise around text and between lines and probably thanks
to this fact, more compression efficiency was achieved. Also some pixel
flipping was observed.
In the graph below, the curves represent how the DJVU JB2 compression becomes
more and more efficient face to the lossless option marked by no. 1.
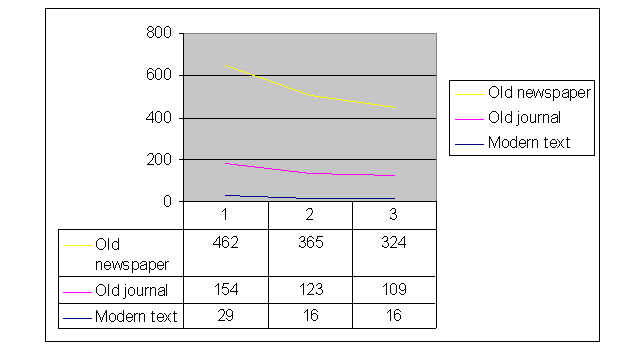 In this graph, the size of the compressed
files marked by no. 2 refers to the lossy option, while that related to
no. 3 to the aggressive option. The modern text file is represented by
the sample no. 4 taken from previous CCITT-based tests. The old journal
file is also taken from previous considerations: in this file, all the
Gothic characters have the same size and there is almost no noise. The
old newspaper file is a large file in which the characters are of different
sizes and types; there is also much noise on this page represented by various
pixel blocks an there are even isolated pixels between lines and around
characters.
In this graph, the size of the compressed
files marked by no. 2 refers to the lossy option, while that related to
no. 3 to the aggressive option. The modern text file is represented by
the sample no. 4 taken from previous CCITT-based tests. The old journal
file is also taken from previous considerations: in this file, all the
Gothic characters have the same size and there is almost no noise. The
old newspaper file is a large file in which the characters are of different
sizes and types; there is also much noise on this page represented by various
pixel blocks an there are even isolated pixels between lines and around
characters.
 It
is quite characteristic that the aggressiveness of compression is most
important in case of the old newspaper. Here, the savings are considerable
and they are very significant for slow Internet connectivity. The nearby
image shows differences in absolute savings in kilobytes, while the intersection
of the three curves is the lossy compression result. It is evident from
here that the aggressive method is relevant for transfer of large files.
It is even more important if we realize that the quality of the data issued
from aggressive compression is very good. The only problems could be only
with low resolution files and very small characters.
It
is quite characteristic that the aggressiveness of compression is most
important in case of the old newspaper. Here, the savings are considerable
and they are very significant for slow Internet connectivity. The nearby
image shows differences in absolute savings in kilobytes, while the intersection
of the three curves is the lossy compression result. It is evident from
here that the aggressive method is relevant for transfer of large files.
It is even more important if we realize that the quality of the data issued
from aggressive compression is very good. The only problems could be only
with low resolution files and very small characters.
 |
However, perhaps more interesting
would be to see the relative efficiency of the three DJVU JB2 options on
these files. This is shown on the nearby graph relatively to the lossless
option. It is evident that the efficiency of the lossy compression is higher
in case of modern text, but there is no progress from lossy option to the
aggressive one. This is caused by high quality and clearness of the modern
text. However, for old documents, the relative savings are not so high:
in both cases only ca. 30%, while the aggressive option saves another ca.
10% face to the lossy one. This is probably caused by better smoothing
of pixel blocks and their better matching to those from the dictionary
and especially by noise removal. Certain role may be also played by quantization
of offsets, but here the gain will be very low [4]. |
 |
We have also observed earlier that
DJVU JB2 lossless option is evidently better than the CCITT G4 lossless
scheme. Another graph shows this comparison enlarged with comparison with
the aggressive JB2 scheme. It can be seen that face to CCITT G4 the JB2
aggressive scheme saves 77% in case of modern text, 43% in case of the
old journal, and 45% in case of the old newspaper page. The files received
from this aggressive compression are very well readable, while for the
normal user and his eyes apparently no inconvenient loss has occurred.
Furthermore, it can be said that more critically can be felt losses happened
during conversion from reality into only bi-level scheme than those - almost
imperceptible - which have taken place during the aggressive lossy compression
in DJVU JB2. |
Scanned versus computer generated
image files
Another very interesting test was made
to discover differences during compression that took place on two images
of the same page. The selected page was taken from an English paper presented
at a conference. It contained only text, short contents and two headings
in another fonts at various sizes. The uncompressed size was 205 KB for
the computer-generated file and 195 KB (after some cutting of unnecessary
space) for the scanned file. Both bi-level files had the resolution of
150 dpi. Here are the results:
 We can guess that the scanned file contained
in spite of good printing some noise and irregularities of pixel blocks,
but both in Adobe Photoshop PDF and TIFF CCITT G4 there were almost the
same compression results also in case of the computer generated file. This
had not been expected. However, more interesting was the situation in case
of the three DJVU JB2 options.
We can guess that the scanned file contained
in spite of good printing some noise and irregularities of pixel blocks,
but both in Adobe Photoshop PDF and TIFF CCITT G4 there were almost the
same compression results also in case of the computer generated file. This
had not been expected. However, more interesting was the situation in case
of the three DJVU JB2 options.
We can see that in both cases JB2
was successful to compress down the file in a very substantial manner.
In case of the scanned file there was another additional compression made
by the lossy encoder. This was probably done thanks to above-mentioned
pre-processing techniques.
As to the computer generated file, the JB2 lossless compression was very
radical and it was not improved either by the lossy or aggressive encoders.
The explanation is very simple: the file was clean of noise and irregularities;
therefore, all the pre-processing and processing techniques could work
at their best. The resulting size was very small: only 7 KB.
Post-processing and access
Access to files compressed with the
discussed schemes is possible either in authoring software6
or in web browsers with installed special plug-ins. There are plug-ins
for DJVU and LDF formats, which are freely downloadable from Internet7.
They give users plenty of opportunities of work with DJVU and LDF images:
zooming, rotation, 'save as' functions, etc.
 Furthermore,
they post-process the image in certain manner so that the user has the
impression that the image has been improved. This is quite pleasant in
comparison with classical black-and-white viewing. If we look closer to
post-processed characters, we can see that their edges have been filled
in with grey pixels. If such an image is scaled down, we have a very soft
impression of good readability. It disappears usually when we enhance the
text too much, because the illusion works better on smaller characters.
This quality is implemented also in some other plug-ins, for example, Watermark
Web Series that enables to work with TIFF format in Netscape and Internet
Explorer browsers. There is also the ImgGear plug-in developed by the Czech
company Albertina icome Praha that, among other formats, makes possible
work with TIFF CCITT G4 scheme in Netscape. Other plug-ins can be found
on Internet, but they are not so many, while only very few of them are
offered as freeware. It seems that Internet access to bi-level documents
will play an important role in the future; therefore, it makes sense to
work on better compression schemes and better access tools to black-and-white
images.
Furthermore,
they post-process the image in certain manner so that the user has the
impression that the image has been improved. This is quite pleasant in
comparison with classical black-and-white viewing. If we look closer to
post-processed characters, we can see that their edges have been filled
in with grey pixels. If such an image is scaled down, we have a very soft
impression of good readability. It disappears usually when we enhance the
text too much, because the illusion works better on smaller characters.
This quality is implemented also in some other plug-ins, for example, Watermark
Web Series that enables to work with TIFF format in Netscape and Internet
Explorer browsers. There is also the ImgGear plug-in developed by the Czech
company Albertina icome Praha that, among other formats, makes possible
work with TIFF CCITT G4 scheme in Netscape. Other plug-ins can be found
on Internet, but they are not so many, while only very few of them are
offered as freeware. It seems that Internet access to bi-level documents
will play an important role in the future; therefore, it makes sense to
work on better compression schemes and better access tools to black-and-white
images.
Conclusion
The tests have shown that there is a
lot of development of new compression schemes for the black-and-white (bi-tonal)
image. Some of them seem to be able to help better Internet transfer and
file management. The problem remains that until today only CCITT G4 has
been implemented in a standardized format (TIFF); therefore, CCITT G4 will
still remain for some time the preferable format for a good part of digital
libraries.
Also our digital library of old newspapers and journals - from which we
took two samples - relies on this scheme and TIFF format. Nevertheless,
there are two ready-to-use solutions for document delivery - LDF and DJVU
- with better coders of bi-level images that the CCITT G4 is. Especially
DJVU for the bi-level image is very promising, because the format is supported
by good authoring and viewing tools from which several ones are offered
as freeware. This is not the case of LDF or other solutions about which
we can only read (e.g. Lightning Strike bi-level encoder by Infinop, Inc.).
It seems that DJVU, as a mixed format, will enjoy of further development:
a DjVu encoder for compressing several pages together is about to be launched.
Thus, the dictionaries for soft pattern matching will be shared between
pages and the compression ratio optimized even more. DjVu is also the format,
which has already implemented the emerging JBIG2 standard and which has
got at its disposal good tools for work.
It also becomes evident that the future is open for lossy compression schemes
for the bi-tonal image. With our tests, we have tried to demonstrate possible
results and problems. We have relied on available solutions and software,
because we think that the free availability of authoring and viewing tools
can contribute to standardization of optimized data formats.
Bibliography
-
Power Compressor 1.04.
Product Description. Vancouver, Image Power, Inc., 1999. 26 pp.
-
Image Power JBIG2 Codec
Performance Compression Efficiencies (http://www.imagepower.com/compress/)
-
The Challenge of Bi-dimensional
Image Transfer over Wireless Data Networks. White Paper. Vancouver, Power
Image, Inc., 1997. 6 pp.
-
information can be found
in:
-
The Emerging JBIG2 Standard / Paul G.
Howard, Faouzi Kossentini, Bo Martins, Soren Forchhammer, William J. Rucklidge,
Fumitaka Ono. 1999, 27 pp.
-
The JBIG Compression Standard: The Future
for Document Imaging (http://www.pdsimage.com/html/news/jbig/whtpaper.htm)
-
High Quality Document
Image Compression with DjVu / Léon Bottou, Patrick Haffner, Paul
G. Howard, Patrice Simard, Yoshua Bengio and Yann LeCun. Lincroft, AT&T
Laboratories, 1998. 25 pp.
-
documentation available
in:
-
LDF plug-in downloadable
from the URL of the LuraTech Comp. http://www.luratech.com,
while the djvu plug-in from the URL of the AT&T laboratories DJVU homepage
http://djvu.research.att.com/
- Tested samples