Obecný problém práce s bázemi dat
Pod obecným pojmem báze dat je celkem snadné si představit velmi široké spektrum nejrůznějších elektronických
informačních zdrojů, které mohou poskytovat jak jen jednoduché, tak naopak detailní a vysoce odborné informace. Tomu pak logicky
odpovídá náročnost práce s takovou bází dat, která může být velmi primitivní nebo naopak vyžadující jak kvalifikaci, tak i
pracovní erudici. Vyšší nároky mají především báze dat z vědecké oblasti, které představují více či méně sofistikované
nástroje pro práci s odbornými a vědeckými informacemi, přičemž míra sofistikovanosti záleží především už na prvním kroku,
tj. na tom, jak detailně byly zpracovány primární informační zdroje do konkrétní sekundární báze dat. Pokud jsou primární
zdroje, nejčastěji tedy články z vědeckých a odborných periodik nebo patenty, zpracovávány jen do podoby bibliografické
citace s názvem práce a abstraktem, doplněné maximálně souborem klíčových slov nebo podobných nástrojů věcného popisu,
navíc dnes nejčastěji automaticky přebíraných z textu názvu nebo abstraktu, nelze očekávat ani přílišnou náročnost práce s takovou
bází dat a pochopitelně ani možnost získání mimořádných informací. Pokud jsou ale primární zdroje zpracovávány tak, že každá
práce je v podstatě prostudována a její obsah vyjádřen souborem různých atributů věcného popisu rozdělených do předem
definovaného systému rovnocenných nebo hierarchicky uspořádaných polí a podpolí, nabízí se uživatelům informační zdroj, který
může být využíván na daleko vyšší úrovni, než jen prostřednictvím zadávání nejčastěji jen několika jednoslovných termínů a
jejich vzájemných logických vazeb. Taková vyšší forma využívání má ale minimálně dva předpoklady:
- poměrně podrobná znalost celkové struktury dané báze dat
- znalost nástrojů pro práci s databázovým systémem neboli znalost dotazovacího jazyka
Znát strukturu báze dat, se kterou pracujeme, je obecně základním předpokladem pro to, abychom dostali vůbec
přijatelné výsledky při vyhledávání informací. Měli bychom vědět, do jakých polí jsou ukládány údaje z primárních
dokumentů, která pole jsou použitelná pro vyhledávání a která jsou určena jen pro zobrazování výsledků, případně která jsou
použitelná pro některé další operace, např. extrakce dalších hodnot polí ze získaných množin odkazů a manipulace s nimi.
Tak např. báze dat Chemical Abstracts má cca 60 polí pro vyhledávání a zobrazování a 35 polí umožňující následné operace selekce
hodnot a jejich třídění. Báze dat organických sloučenina Beilstein a anorganických sloučenin Gmelin mají data uložena v několika
stech pojmenovaných polí (báze dat CrossFire Gmelin má až 800 polí). Chceme-li tuto strukturu polí využít, musíme mít k disposici
buď stručný manuál nebo nějakou vhodnou formu zobrazení struktury polí při vlastní práci.
Ještě závažnější je otázka znalosti dotazovacího jazyka, který sice zpravidla neoplývá množstvím příkazů, ale
spíše jejich syntaxí a parametrizací. Tak např. nejdůležitější příkaz SEARCH pro vyhledáváni ve všeobecně uznávaném velmi
dokonalém dotazovacím jazyku Messenger® pro práci s bázemi dat ve středisku STN International je v manuálech
ilustrován v 60 různých syntaktických variantách. Důsledkem je pak jednak výchozí požadavek naučit se dotazovací jazyk pro
databázový systém nebo pro danou bázi dat, se kterou chceme pracovat, používat a pak ještě důležitější požadavek, získanou
znalost práce s dotazovacím jazykem udržet na rutinní úrovni. Je totiž prakticky vyloučené pracovat s nějakou bází dat
tak, že jsme nuceni neustále vyhledávat správnou formulaci dotazu v manuálech. Tato situace je všem producentům bází dat z oblasti
vědy a techniky velmi dobře známá jako jeden z nejdůležitějších aspektů limitujících extenzivní využívání těchto, jinak
zpravidla mimořádně silných nástrojů práce s vědeckými informacemi. Proto jakmile to bylo možné, především jakmile se
objevila grafická rozhraní, začaly se objevovat různé nástroje usnadňující práci, nejčastěji v podobě formulářů, ve kterých
je možné zadávat názvy polí výběrem z jejich rozbalovaných seznamů, formulováním složitějších dotazů zadávání termínů do
víceřádkových formulářů a řadou dalších zjednodušení. Logickým důsledkem ale prakticky každého zjednodušení je omezení
vyhledávacích možností a tím i nemožnost plně využít potenciál dané báze dat. Klíčová otázka je pak nalezení optimálního
kompromisu mezi nutností naučit se strukturu bází dat a práci s dotazovacím jazykem a naopak nabídkou takových
“user-friendly” nástrojů, které umožňují, aby si uživatel sedl k počítači v okamžiku, kdy potřebuje informace a bez
problémů mohl s daným informačním zdrojem pracovat a hlavně získat pokud možno stejné výsledky, jako při práci se
sofistikovaným dotazovacím jazykem.
Tato situace, která se v první řadě projevuje u bází dat z oblasti vědy a techniky, je ale zcela
obecná a ve větší či menší míře se s ní setkáme u bází i z jiných oblastí. Je přirozené, že zkušenosti a poznatky s prací
s bázemi dat vědeckého a odborného charakteru, budou využívány ve vhodné míře i u dalších bází dat.
Báze dat Chemical Abstracts a možnosti jejich využívání
Chemical Abstracts je typickým příkladem báze dat, do jejíhož vytváření je vkládán značný podíl přidané
hodnoty, jak ve formě rozsáhlého a propracovaného víceúrovňového indexování, tak hlavně tím, že jsou excerpovány všechny v primárních
dokumentech se vyskytující chemické sloučeniny, jejichž rejstříkové soupisy obsahující i grafickou strukturní reprezentaci
představují naprosto nezastupitelný nástroj vědecké práce v chemických oborech. Rozsah polí, ve kterých jsou uloženy
jednotlivé položky jmenného a věcného popisu, jsme uvedli v předchozím odstavci, možnosti práce s jednotlivými
složkami identifikačního popisu chemických sloučenin jsou ještě větší. Využít tyto možnosti bylo sice možné prakticky od samého
počátku síťového zpřístupnění báze dat CA, ale vždy taková práce představovala poměrně náročný úkol vyžadující určité zaškolení
a pak udržování pracovní rutiny. Plně kvalifikovaná práce s bází dat CA byla a stále je možná jen v databázovém
středisku STN International a vyhledávacího jazyka Messenger®. Jakmile se objevily jiné, více “user-friendly”
možnosti zpřístupnění, producent se snažil je nabídnout. Nejdříve to bylo např. zpřístupnění báze CA v prostředí
databázových středisek DIALOG nebo Datastar. Později byl vyřešen způsob, jak distribuovat bázi CA na médiu CD-ROM a s touto
verzí označovanou jako “CA on CD” přišel i poměrně dokonalý vyhledávací systém, který už představuje skutečný kompromis mezi
snadností práce s bází dat a nemožností plně využít její potenciál. Vývoj šel ovšem dále a tak v roce 1997 nabídl
producent báze CA, Chemical Abstracts Service, prvou verzi programu pro práci s bází, který maximálně využívá stávající
webovské technologie na straně jedné a komunikační možnosti Internetu na straně druhé. To znamená, že program pracuje s celou
bází uloženou na serveru ve Spojených státech a díky současnému kvalitnímu spojení prakticky bez vážnějších problémů. Tento
program, uvedený na trh pod komerčním označením SciFinder®, vyvolal svým řešením velkou pozornost, získal řadu
uznání
a ocenění na výstavách a přes vysokou cenu se rychle prosadil v praxi. V současné době tento program představuje
nejpokročilejší řešení problému naznačenému v úvodu této přednášky, tj. nabízí svým uživatelům velmi silné nástroje pro
práci se sofistikovanou bází dat jako je báze Chemical Abstracts, které jim umožňují získat výsledky srovnatelné s výsledky
profesionálních rešeršérů bez nutnosti absolvovat extenzivní školení a následné udržování pracovní rutiny. Hlavním heslem autorů
programu je možnost intuitivní práce na daleko vyšší úrovni, než jen prostřednictvím volby textových hesel a jejich logickými
vazbami. Je proto účelné demonstrovat tento program podrobněji.
Program SciFinder®
Tento program pro práci s elektronickými soubory Chemical Abstracts je zatím posledním vývojovým
stupněm zpřístupňování těchto informací. Jinak lze program SciFinder® charakterizovat jako další krok ve snaze
přivést konečného uživatele, chemika nebo chemického inženýra řešícího výzkumný problém, zpět k bezprostřednímu kontaktu s
chemickými informacemi. Nelze totiž přehlédnout, a producenti sekundárních zdrojů jsou si toho dobře vědomi, že přechod od
tištěných zdrojů ke zdrojům elektronickým není tak jednoduchý a přímočarý, jak na první pohled vypadá a určitou část pracovníků,
především starší, ale i střední generace, elektronický přístup odrazuje. Mladší generace sice zpravidla nemá žádné zábrany
využívat Chemical Abstracts v elektronické podobě, často už tištěnou verzi zcela odmítá a většinou je schopna získat více
či méně odpovídající výsledky, ale často zdaleka nevyužívá potenciál, který elektronická podoba sekundárních zdrojů nabízí.
Zatímco nejdůležitější nástroje práce se sekundárními zdroji, rejstříky, ve své tištěné podobě umožňují do značné míry
intuitivní práci v pravém slova smyslu, jejich elektronická forma nabízí sice daleko více možností, efektivitu práce i komfort,
ale přece jenom vyžaduje, aby se uživatel seznámil s její strukturou a i dohodnutými pravidly. Dochází pak k tomu, že uživatel,
který byl zvyklý pracovat s tištěnými zdroji, může být při přechodu na elektronické verze nespokojen s dosaženými výsledky a
uživatel, který zkušenost s tištěnými rejstříky nemá, inklinuje k tomu, spokojit se s náhodně získanými informacemi. Někteří
uživatelé pak rezignují na bezprostřední práci s elektronickou bází a přenechávají tuto činnost zprostředkovatelům, nebo, pokud
pracují sami, informační potenciál dané báze nevyužívají. V konečném důsledku pak producenti, v daném případě Chemical
Abstracts Service, přicházejí o uživatele a tím i o zákazníky a vědečtí pracovníci přicházejí o cenné informace.
Před podrobnějším popisem programu a práce s ním je nutné se zmínit o možnostech jeho využívání z hlediska
chemika pracujícího ve výzkumu a i o otázkách jeho ceny. Program SciFinder® byl uveden na trh v r. 1997,
právě
pod tímto označením, ale byl nabídnut pouze chemickému průmyslu pro instalaci v lokálních, uzavřených sítích, tedy jako
intranetovská verze. Akademické instituce, ani podobné neziskové výzkumné instituce tento program nemohly získat. Teprve asi po
dvou letech byla otevřena možnost práce s tímto programem i pro univerzity, kterým byla nabídnuta verze označovaná
SciFinder® Scholar. Ve skutečnosti se nejedná o dvě verze tohoto programu, méně rozsáhlou nebo snad
výkonnou,
ale o dvě zásadně odlišné formy finanční úhrady za její využívání. Verze SciFinder pro průmysl vyžaduje úhradu na základě
skutečného využívání, tj. počtu dotazů, objemu převzatých informací, době využívání a i dalších faktorech, podle více modelů a
různých možností v závislosti na velikosti podnikového výzkumu apod. Nejedná se tedy o předplatné, ale o měsíční fakturaci.
Naproti tomu verze SciFinder® Scholar pro univerzity, pro které je způsob průběžně narůstajících nákladů
nepřijatelný, je zpřístupňována na základě ročního předplatného tak, jako u naprosté většiny podobných bází dat. Je ale nutné
dodat, že výše předplatného je vysoká a je vázána na počet současně pracujících uživatelů. Pro představu je možné uvést, že v r.
2001 bylo předplatné pro verzi SciFinder® Scholar s právě jedním současně pracujícím uživatelem pro univerzitu s
doktorandským programem kolem 1 mil. Kč.
Stručná charakteristika programuSciFinder®
Tak především program SciFinder® v sobě spojuje obě hlavní báze Chemical
Abstracts,
tj. vlastní bibliografickou bázi CA v nejsilnější verzi CAplus, s bází chemických sloučenin REGISTRY. Pracujeme tedy současně s
bibliografickými záznamy i se strukturami. Připomeňme, že báze REGISTRY je samostatně přístupná jen v databázovém středisku STN
International a za použití jazyka Messenger®. Možnost pracovat se strukturami má ale dvě úrovně. V základní
verzi programu jsou graficky reprezentované struktury zobrazovány a můžeme je vyhledávat v přesně zadaném tvaru (tedy jako
tzv. Exact Search). V rozšířené verzi za zvláštní příplatek je možné struktury otevírat pro substituce kdekoliv nebo
jen na předem určených místech molekuly a pracovat v režimu substrukturního vyhledávání (Substructure Search). Tato
možnost je označována jako práce s modulem SSM. Dále byly do programu SciFinder® integrovány i báze
CHEMLIST,
tedy souhrn všech známých legislativních předpisů týkajících se chemických látek a báze CHEMCATS neboli souhrnný katalog
komerčně dostupných chemikálií. Ještě významnější je zahrnutí báze chemických reakcí, neboli báze CASREACT. Kromě toho je
současně implicitně nabízen přístup do báze MEDLINE. Program pracuje s maximálně možným časovým rozmezím elektronických
materiálů CAS, který dlouhou dobu začínal (a končil) v r. 1967, v r. 2001 byl rozšířen do, resp. od r. 1947 a v r. 2002 už
zahrnuje celé období existence CA od r. 1907.
Práce s programem SciFinder®
Jak vyplývá z výše uvedené koncepce, program SciFinder® se snaží co nejvíce
eliminovat
nutnost zadávat data do definovaných polí v přesném tvaru, ať již jako řádkové příkazy nebo do formulářů. Jak jsme již uvedli,
jedním z hlavních marketingových argumentů tohoto programu je intuitivní ovládání, které nevyžaduje předběžné školení ani
rozsáhlé manuály. Je ale nutné konstatovat, že to platí tehdy, pokud je uživatel dostatečně seznámen s celým systémem
zpracovávání primárních informací v CAS. V každém případě je i zde nutné varovat před přístupem k programu
SciFinder®
jako k černé skříňce a očekávat, že intuitivně je možné přijít opravdu na všechno.
Výchozím nástrojem pro práci je obrazovka nabízející řadu režimů práce volitelných prostřednictvím ikon. Kromě
evidentních možností, jako je vyhledávat informace na základě znalosti jejich autora (Author Name) nebo vyhledávání prací
podle pracoviště autorů (Company Name/Organization), jsou to především první dvě ikony, z nichž první otevírá vyhledávání
chemických sloučenin (Chemical Substance or Reaction) a druhá vyhledávání informací prostřednictvím jejich věcného popisu
předmětovými hesly neboli na koncepčním principu. Tento režim je označen jako Research Topics. Tyto dvě možnosti jsou
samozřejmě daleko nejdůležitější a probereme je proto podrobněji. Na vstupním okně si všimněme ještě dvou zbývajících ikon, z
nichž jedna (Document Identifier) umožňuje přímo vyhledávat abstrakty primárních dokumentů máme-li na ně odkaz, ale
daleko zajímavější je skutečnost, že do této možnosti bylo zahrnuto i přímé vyhledávání patentů podle jejich označení kódem země
a číslem patentu. Poslední ikona (Browse Table of Contents) je pak vlastně alternativou známých Current Contents,
jedná se tedy o zpřístupňování obsahů jednotlivých čísel vědeckých časopisů tak, jak vycházejí. Všechny tyto výchozí možnosti
jsou sumarizovány na první obrazovce, se kterou začínáme jakoukoliv práci s programem SciFinder®. Pro
nechemika
bude zajímavější práce s koncepčními charakteristikami než vyhledávání chemických sloučenin.

Obr. 1 Vstupní obrazovka programu SciFinder®
Vyhledávání informací prostřednictvím koncepčního popisu
Pro tuto možnost je určena druhá ikona označená na obr.1 jako Research Topics. Po jejím
stisknutí se nám otevře okno, do kterého můžeme formulovat náš dotaz. V souladu s celkovou koncepcí programu SciFinder®
je tento krok řešen tak, aby uživatel nemusel přemýšlet o sestavení dotazu za pomoci logických operátorů a seskupení
požadovaných hesel a termínů do množin pomocí závorek, ale formuloval svůj problém tak, jak je zvyklý, tj. normální větou. Takže
např. můžeme napsat následující zadání:
Manufacture of acetone by catalytic dehydrogenation of isopropyl alcohol
Program SciFinder® takto formulovaný dotaz zpracuje tím způsobem, že identifikuje
jednotlivé
koncepční termíny a místo předložek, spojek nebo členů, které je spojují, vloží postupně logické operátory s těsnější nebo
naopak volnější vazbou. Nejdříve takto zpracuje všechny identifikované koncepční termíny a vytvoří jednu nebo několik množin
odpovědí. V dalším kroku pak opět postupně jednotlivé termíny vypustí a opět vytváří množiny odpovědí. Celkovým výsledkem
hledání je seznam souborů odpovědí s různou vazbou mezi všemi, nebo jen některými koncepčními termíny, jehož část je
ilustrována na dalším obr. 2.

Na základě této nabídky různých kombinací termínů pak můžeme zvolit zaškrtnutím ty, o kterých se domníváme, že
nejlépe odpovídají našemu záměru (principiálně libovolný počet těchto výběrů) a příkazem (tlačítkem) Get References
zobrazit seznam skutečných odkazů jako výsledek zadání dotazu. S takto získaným výsledkem jsme buď spokojeni nebo s ním
dále pracujeme. Malá část výstupu seznamu odkazů je na obr. 3, který má spíše ilustrovat právě nabídku možností další práce.

Nejzajímavější je právě funkce Analyze or Refine References, pod kterou je skryta řada možností
upřesňování souboru odkazů a budiž řečeno, že termín analýza souboru odkazů není příliš nadsazený a poměrně přesně vystihuje, o
co jde. Kromě řady celkem běžných procedur upřesňování souborů bibliografických dotazů, jako je jejich omezení jen na určité
typy dokumentů, např. vyloučením nebo naopak vybráním jen patentových spisů nebo volbou jen knih nebo referátových článků,
omezení na určité časové období apod., což je zahrnuto pod termín Refine, analyzovat soubor odkazů je chápáno jako
extrakce termínů z řady dalších polí všech odkazů a jejich seřazením alfanumerickým nebo frekvenčním jako podklad pro
rozhodování o dalším výběru dokumentů.
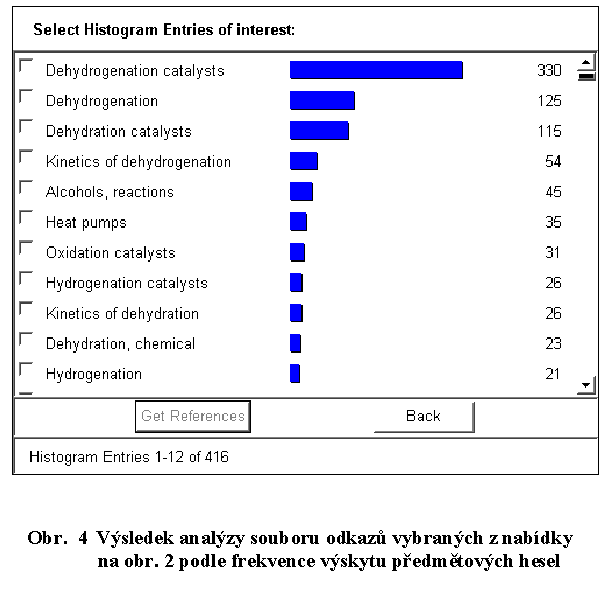
Ilustrace výsledku takové analýzy souboru bibliografických odkazů, která byla realizována vybráním všech hesel
v poli Index Terms jednotlivých odkazů a jejich v daném případě frekvenčním seřazením je na obr. 4. Kromě
bezprostřední informace o rozložení zájmu o danou problematiku, tak získáváme i nabídku dalších termínů jako inspiraci pro
upřesnění rešerší (hlavně pokud výsledek analýzy zobrazíme v abecedním řazení) nebo rovnou vybereme soubory odpovídající
jednomu nebo více upřesňujícím heslům. Obdobnou analýzu je možné provést pro řadu polí, např. podle autorů, firem, roků vydání
dokumentů a dalších. Volba polí pro analýzu ale není libovolná, můžeme volit pouze z nabídky, která je zobrazena v okně
otevřeném volbou funkce Analyze or Refine Reference. Je zřejmé, že je možné analyzovat soubor odkazů podle jednoho
kriteria, vybrat užší soubory a analyzovat podle dalších kriterií. V každém případě představuje možnost analyzovat primární
získaný soubor odkazů podle řady aspektů velmi zajímavý a účinný nástroj práce s vědeckými informacemi.
Vyhledávání chemických sloučenin
Tato možnost je z hlediska konečného využití programu SciFinder® samozřejmě ještě
významnější než práce s koncepčními termíny, ocení ji samozřejmě profesionální chemici. Pro širší veřejnost se proto
omezíme jen na ilustrativní popis možností charakterizující právě další vývoj podobných programů pro práci s bázemi
vědeckých informací.
Pro vyhledávání chemických látek a sloučenin nabízí program SciFinder® tři výchozí možnosti,
zadávání dotazu prostřednictvím sumárních vzorců (Molecular Formula), pomocí názvů (Substance Identifier) nebo
jako nejuniverzálnější možnost nakreslením hledané struktury (Chemical Structure). Jako ilustraci snah po zjednodušení
práce uživatelů je možné uvést zadávání názvů hledaných látky prakticky v jakékoliv formě, tedy nikoliv bezpodmínečně v té
jedné jedině správné. Tak např. v případě systematických názvů program SciFinder® provede sám inverzi názvu
do
podoby používané v Chemical Abstracts. Jak nás upozorňují již příklady v otevřeném okně této volby, můžeme zadávat
název sloučeniny ve tvaru 1,4-dichlorobenzene místo správného: Benzene, 1,4-dichloro-. Stejně tak můžeme použít tzv. triviální
názvy, které jsou jinak nepřípustné.
Nejsilnějším nástrojem pro vyhledávání chemických sloučenin je samozřejmě strukturní editor, který se otevře po
volbě Chemical Structure v okně vyhledávání sloučenin. Není zajisté překvapující, že tento editor umožňuje
formulovat strukturní dotaz se všemi aspekty, které digitalizovaná reprezentace struktury chemické sloučeniny nabízí, tj.
otevírat posice pro další definované nebo libovolné substituce, deklarovat alternativní kvalitu atomů na určených místech
struktury nebo povolovat či naopak zakazovat uzavírání kruhových substitucí. To, čím se program SciFinder®
odlišuje,
jsou opět možnosti dalšího zpracování primárně získaných souborů, v tomto případě nikoliv bibliografických odkazů, ale
struktur chemických sloučenin. Pro ilustraci uvedeme poměrně jednoduchý příklad, kdy hledáme sloučeniny, které ve své molekule
obsahují cyklopentapyrimidinové seskupení a pro další substituci jsou otevřeny jen dva atomy (viz obr. 5). Z výsledného souboru
cca 200 sloučenin je nejvíce takových, ve kterých je k dané struktuře připojen další cyklický systém. Program
SciFinder® má v sobě zabudovánu možnost analyzovat strukturní soubor právě podle charakteru kruhů, které
sloučeniny obsahují. Výsledek takové analýzy na obr. 6 ukazuje jednak přítomnost dalších cyklických systémů v jednotlivých
sloučeninách a jednak i jejich počet. Je to tedy analogické frekvenční analýza souboru struktur tentokrát podle výskytu
kruhových složek.
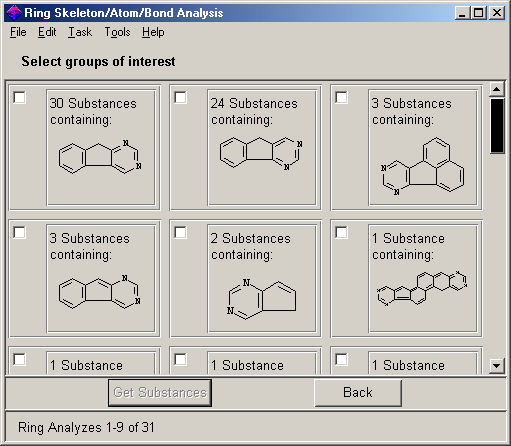
Obr. 6 Výsledek analýzy souboru struktur podle cyklických systémů přítomných v molekulách
Jako další krok je možné celý soubor nebo jen vybraný soubor na základě analýzy kruhů, podrobit analýze podle
charakteru atomů připojených na zvolená místa struktury. Ilustraci o této možnosti podává obr. 7, na kterém je vidět, že pro
daný atom (označený červenou šipkou) existuje několik druhů připojení, které si buď vybereme nebo nás nezajímají. Z výsledku
vidíme, že 5 sloučenin nemá v požadovaném místě žádnou další substituci vyjma atomu vodíku, 19 sloučenin má zde uhlíkatý
zbytek a stejný počet jakékoliv připojení, tedy nikoliv jenom uhlíkaté (soubor se bude pravděpodobně shodovat s předchozím).
Celkové zhodnocení programu SciFinder®
Program SciFinder® nabízí pochopitelně celou řadu dalších
možností
práce a zabudovaných nástrojů pro upřesňování nalezených souborů informací a označení těchto funkcí termínem Analyze není
v žádném případě přílišnou nadsázkou. Je ovšem nutné si uvědomit, že tyto možnosti jsou k dispozici už poměrně dlouhou
dobu jako součást profesionálních dotazovacích jazyků, nejvýrazněji v případě jazyka Messenger ® pro práci s bázemi
dat uloženými v databázovém středisku STN International. Pro uvedené ukázky excerpce termínů z určených polí vybraných
dokumentů je to příkaz Select, resp. navazující SmarSelect a další příkazy pro třídění a následné manipulace. V tomto
případě je ovšem nutné se naučit tyto příkazy používat včetně všech souvisejících parametrů a akceptovat průběžně navyšované
náklady na práci, které budou samozřejmě také záviset od toho, jak kvalifikovaně a “chytře” jsou tyto nástroje používány. To
opět závisí na charakteru dotazu, v některých případech může být taková analýza velmi efektivní, v jiném spíše ztráta
času a peněz.
Zajímavá a velice ilustrativní je jiná věc. Příkazy dotazovacích jazyků, konkrétně jazyka
Messenger®,
umožňují např. volit daleko větší spektrum polí pro analýzu, zatímco program SciFinder® jen takové, které jsou
nabídnuty a jsou součástí programu. Jinými slovy, jestliže báze dat Chemical Abstracts nabízí pro použití příkazu Select cca 55
polí, z nichž velká část se týká popisu patentových dokumentů, pak program SciFinder®,
alespoň ve verzi Scholar, jich nabízí maximálně dvacet a žádné z oblasti detailnějšího popisu patentů. Je to
ilustrace toho, že provádění rešerší prostřednictvím profesionálních dotazovacích jazyků je stále považováno za nejsilnější
nástroj rešeršní práce s vědeckými a odbornými bázemi dat a profesionálním rešeršérům je zde ponecháván patřičný
prostor.Nakolik je tento stav výsledkem kompromisu mezi snahou co nejvíce zjednodušit přístup k sofistikovaným informacím
koncovým uživatelům a současně neomezit potenciál informačního zdroje nebo rozhodnutím zachovat práci profesionálním rešeršérům,
kteří stále představují velmi důležité zákazníky databázových středisek a tím i producentů bází dat, ukáže až další vývoj. V současné
době představuje program SciFinder® nepochybně velmi zajímavý vývojový stupeň v nabídce
klientských programů, který zatím od doby svého uvedení na trh nenašel výraznější konkurenci. Je proto určitě velmi důležité, že
se na konci r. 2001 díky podpoře programu podpory informačního zabezpečení vědy a výzkumu v České republice vypsaného
Ministerstvem školství, mládeže a tělovýchovy (program LI), podařilo zpřístupnit program SciFinder® pro prakticky
všechny chemické fakulty v České republice.
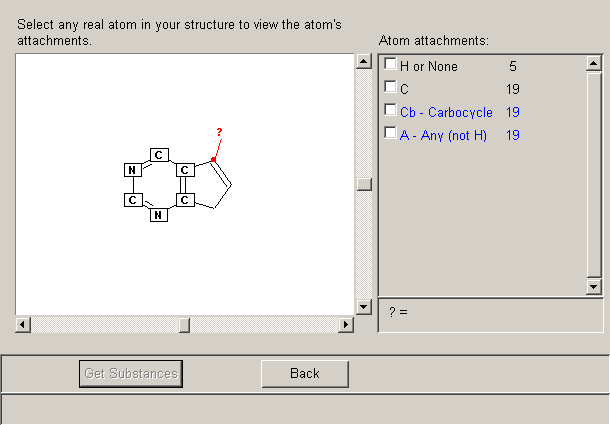
Obr. 7 Nástroj pro analýzu charakteru připojení pro zvolený atom výchozí struktury
Literatura:
- bližší podrobnosti o programu SciFinder® je možno získat na adrese: www.cas.org
- SciFinder Scholar 2001
. User Guide. American Chemical Society 2001.
- Ridley D.: Information Retrieval, SciFinder and SciFinder Scholar. Wiley College Textbooks, Wiley, New York 2002.
- Šilhánek J.: Chemická informatika. Vydavatelství VŠCHT Praha 2002, v tisku.
|
