Abstract:
During the last few years, the World-Wide Web has become one of the most widespread technologies of information presentation. Because of its enormous growth, the task to find an information about a specific topic can be very hard. Search engines were developed to automatize this process. Nevertheless, “classical” search engines can have significant drawbacks for a common unexperienced user (different locations, different interface etc.).
The aim of the Vševěd metasearch system is to simplify search for information (Web pages) on the Internet. The system was inspired by some existing metasearch systems, mainly by AskJeeves. Our system differs mainly in its focus on czech environment (czech language, czech search engines).
During the last few years, the World-Wide Web has become one of the most widespread technologies of information presentation. Because of its enormous growth, the task to find an information about a specific topic can be very hard. Search engines help to automatize this task by looking for a Web page according to words/phrases given by the user. Search is based on off-line (manually - e.g. Yahoo, or automatically - e.g AltaVista) created indexes. Standard way of using a search engine consists of a sequence of actions:
The use of search engines can have significant drawbacks for a common (unexperienced) user. There is a number of search engines at different locations each having its own ways of interaction with users. So the user must remember their URL and the way how to work with them. So the idea of “metasearch” emerges to help users to find relevant information in a more convenient way. The basics of all metasearch engines is to give access to more than one search engine. Sharing this idea the abilities of different systems can vary:
Advantages of metasearch are:
The aim of the Vševěd metasearch system is to simplify search for information (Web pages) in the Czech Internet. The system was inspired by AskJeeves, a metasearch engine, that uses both local database and “standard” search engines (e.g. AltaVista, Lycos, Infoseek, Excite) to find infromation relevant to users query. Unlike AskJeeves, our system is oriented on czech environment (czech language, czech search engines).
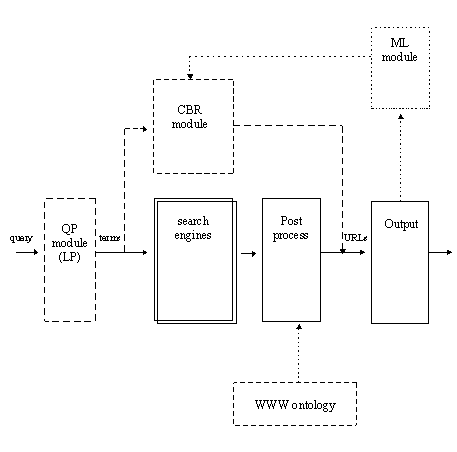
Our work is focused on pre- and postprocessing. With the exception of CBR module, we do not solve the question of search in Internet.
Fig. 1 Overall scheme of the system
The main scheme of Vševěd is shown on Fig. 1. The core modules are working now, the intelligent modules are rising gradually. Full line denotes already realized modules, dashed modules are under development and dotted line means planned modules.
The Vševěd has following components:
The consultation with Vševěd will be as follows:
Following the rapid prototyping paradigm of developing software, we deployed a rather simple first version, which will be gradually extended. This section describes both current state of the modules and their further development.
The minimal realised core of Vševěd consists of:
The “intelligent” part of the system is spread in following modules:
Preprocessing of the query seems crucial for bridging the gap between unskilled users and search systems. The usual way of querying - input of sequence of keywords - cannot benefit from some smart capabilities of different search engines. By now, the preprocessing consists of
Further extensions will be
The processing of the query given in plain (czech) language necessarily includes a solution of these tasks:
Including a thesaurus for expanding the query by equivalent, broader/narrower or otherwise related terms might certainly be of use. We can benefit form previous work on automatic translantion of queries into databases [Strossa].
The result of such preprocessing will be a formula using both boolean operators (and, or, not) and proximity operators (near).
Standard search engines are the main source of inforamtion, the user is looking for. In the current implementation, the user must select the engines he wants to use from the given list (see Fig. 2). The user may choose to test the accessability of pages, but this option takes some additional time.
Possible extension of this module is to select (according the query and Vševěd’s experience) only the most relevant search engines. Such approach is used e.g. in the system SaavySearch.
The result of the search is a list of relevant links. We use the information about URL’s and ‘names’ (content of the HTML tag TITLE) for further postprocessing.
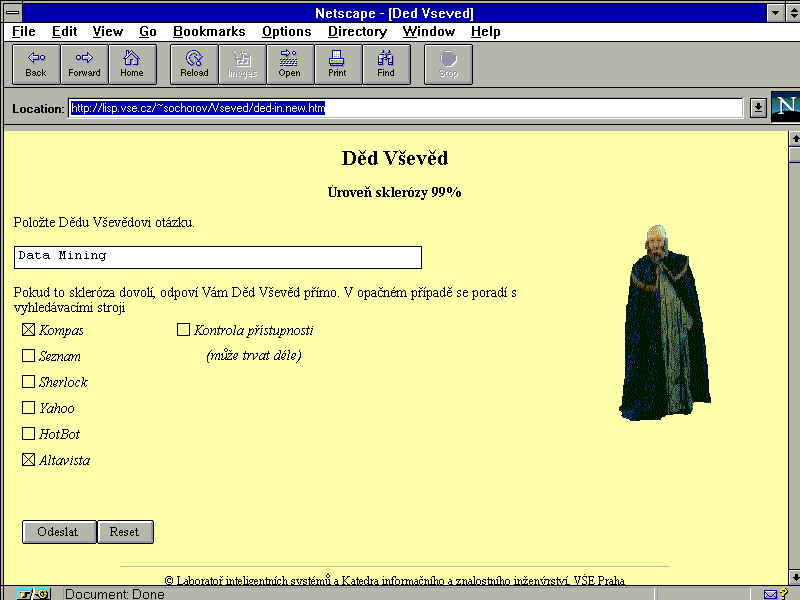
Fig. 2 Vševěd input form
The postprocessing module should better organize the results obtained from different search engines. This can be achieved by
Some of this postprocessing steps have been already implemented, another are under development. By now, the postprocessing is based only on the syntax of the links (URLs). We decompose the URL returned from search engines into server, path, owner, file, first and extension part.
E.g. if the URL is http://lisp.vse.cz/~sochorov/Vseved/main.new.cgi, then
server ...
lisp.vse.cz
path ...
/~sochorov/Vseved
owner ...
~sochorov
file ...
main.new
first ...
main
ext ... cgi
We defined some heuristics to:
We make also an URL-based analysis of the type of the page, e.g.:
For each retrieved link (page) we compute the relevance rel as:
| relmax | if link points to a directory with more relevant pages, |
| relmin | if corresponding page has empty TITLE tag, |
| w1 (a/a+b) + w2 (a/a+c) | elsewhere. |
where a is the number of the words occuring both in the query and page description
a+b is the number of the
words in the query
a+c is the number of the
words in the page description TITLE
The relevance is used to create a sorted output.
Instead of symetric relation between words in the query and in the document description (e.g. a/a+b+c) we give more weight on the first term a/a+b. So we prefer the documents that are described using all words in the query. The idea behind is that a common, “lazy” user gives only the necessary terms in his query.
In the current implementation, w1 = 100 and w2 = 1 (this setting corresponds to sorting using a/a+b as the primary key and a/a+c as the secondary key, rel being from the interval (0, 101]), relmax = 102 (links to a directory obtain the highest relevance) and relmin = 0 (links with empty TITLE obtain the lowest relevance).
Further extensions of the postprocessing will include
For knowledge-based tasks related to Internet (and WWW, respectively), knowledge modeling techniques seem to suit well for capturing static domain knowledge describing e.g. the typical internal structure and mutual links among WWW pages. Heuristics based on such reusable conceptual knowledge bases (ontologies) will be used for postprocessing of the results of search (recognizing type of page, recommending similar pages..).
Creating WWW ontologies is a subject of related research [Šimek, Svátek 1998].
The CBR module should give direct answers to some common questions. Instead (or parallel) to the search in the Internet, the CBR module will search its local case base of links. The case base will be organized in a tree in a way similar to Yahoo-like indexes. The is-a hierarchy will be used to retrieve cases that not only correspond to the user query but are similar in the sence of general/specific relation.
First version of the CBR module is based on the idea that both query nad case description consists of set of words. On this word level (when looking just for word matches), we can obtain
{Query.terms} = {Case.description}
e.g. {data, mining} = {data, mining}
in this situation, the result will be the matching case,
{Query.terms} É
{Case.descriptions}
e.g. {data, mining, and, knowledge, discovery} É {data,
mining}
in this situation, the results will be the general case and its “childrens”
{Query.terms} Í
{Case.popis}
e.g. {data, mining} I {data, mining, and, knowledge, discovery}
in this situation, the results will be the specific case, its “parent” and its “siblings”
e.g. {data, mining} Ç {OKD, mining, company} = {mining}
In case of partial answer and no answer, no case will be retrieved from the case base.
For each retrieved case, we compute the relevance as
(a/a+b+c)
where a is the number of the words occuring both in the query and case description
a+b is the number of the
words in the query
a+c is the number of the
words in the case description
The prototype consists of two parts:
The module searches all records from mysql database that contains some term from the query, their ‘parents’, ‘siblings’ and ‘children’ in the hierarchy. These records are processed by CLIPS rules. We don’t have the taxonomy of Czech words now so we have synonyms in related terms.
The further development of the CBR module will be towards better organization of cases (DAGs instead of trees), better reprezentation of case description and better similarity measures.
The case base is created manually by now, in further step, we assume to use machine learning methods to update this base automatically.
The answers from all engines are shown on one HTML page as a (index) list of links together with some additional information obtained during postprocessing (relevance, types of page). The links are sorted according to the estimated relevance. The links followed by the user are stored for further analysis in (not yet realized) ML module.
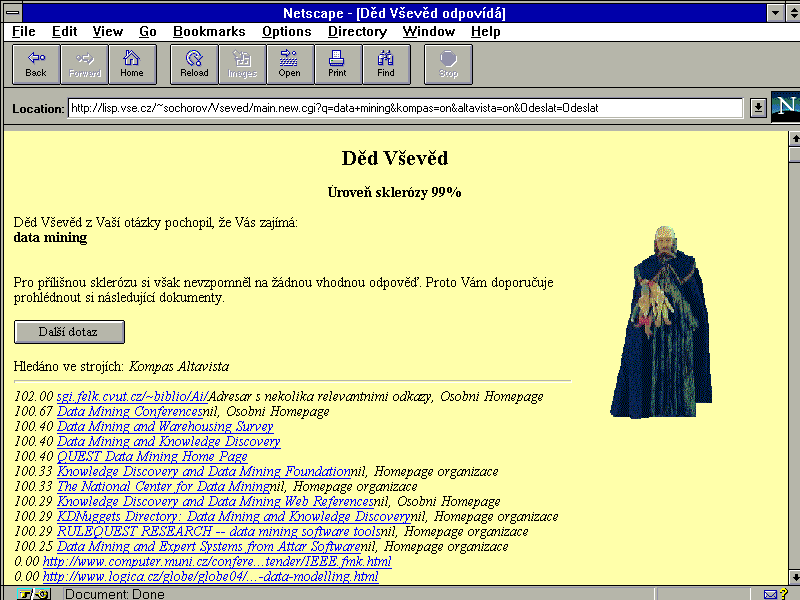
Fig. 3 Vševěd results
Possible development
Vševěd is written in PERL, uses the database mysql and CLIPS (C Language Integrated Production System). Because of its rule-based programming paradigm, CLIPS is suitable for encoding of the postprocessing knowledge. It’s drawback is that the computation is rather slow.
The current version of the system can be found at http://lisp.vse.cz/~sochorov/Vseved/ded-in.htm. Multiple users may use it without an accident, temporary files are generated dynamically.
[Aha, 1991] Aha,D. - Kibler,D. - Albert,M.: Instance-based learning algorithms. Machine Learning, 6, 1991.
[Etzioni, 1997] Etzioni,O.: Moving Up the Information Food Chain. AI Magazine Vol. 18, No. 2, 1997.
[Howe, 1997] Howe,A. - Dreilinger,D.: SavvySearch - A Metasearch Engine That Learns Which Search Engines to Query. AI Magazine Vol. 18, No. 2, 1997.
[Luke, 1997] Luke, S. - Spector, L. - Rager, D: Ontology-Based Knowledge Discovery on the World-Wide Web. In: AAAI96 Workshop on Internet-based Information Systems.
[Mladenic, 1997] Mladenic,D.: Machine Learning on non-homogeneous, distributed text data. PhD thesis proposal, 1997.
[Popovič, 1990] Popovič, M. - Willett, P.: Processing of Documents and Queries in a Slovene Language Free Text Retrieval System. Literary and Linguistic Computing, Vol. 5, No. 2.
[Popovič, 1992] Popovič, M. - Willett, P.: The Effectiveness of Stemming for Natural-Language Access to Slovene Textual Data. Journal of the American Society for Informational Science, Vol. 43, No. 5.
[Strossa, 1994] Strossa, P.: Zpracování informačních fondů; — sešit č. 2: Algoritmizace a automatizace zpracování textových informací. Praha, VŠE 1994.
[Šimek, Svátek 1998] Šimek, P. - Svátek, V.: An Integrated Ontology for the WWW. Submitted to EKAW’99.