|







New Image Formats and Approaches for Document Delivery and Their Comparison with Traditional MethodsAdolf Knoll, National Library of the Czech Republic Efficient delivery of image data consists of an acceptable reduction of information. The paper concerns efficiency of new mixed raster content approaches in comparison with traditional methods such as changes in resolution, colour depth, or compression. The paper is complemented with many comparison tables and applicable samples To be able to read this study, you should have a browser, which supports the PNG image format. The latest versions of MSIE and Netscape do this. If you want to see also special samples, it will be necessary for you to install also two plug-ins for viewing the LuraDocument and the DjVu images. Install the newest versions of plug-ins - in case you have older versions, please de-install them prior to install the new ones. You will find the plug-ins on the web sites of the Luratech Company and the Lizardtech Inc. They will be referred as browser plug-ins.
CONTENTS I Traditional methods
Delivery of scanned documents in image format over networks requires transfer of large quantity of data. In order to reduce it and make the life of end users easier, we should reduce the volume of image files. We have several possibilities how to do it, but in practice the best solutions consist in combining two or more of them. Here are the methods:
The space (spatial) resolution is most frequently called simply resolution and it says how many dots, i.e. elements of the picture (picture elements = pixels) are used to express information found on a unit of length. The most used unit of length is inch; therefore, the resolution is given in dots per inch (dpi). However, it can be measured also per other units of length as, for example, meters or centimetres. The usual desktop scanners scan by default true colour images (frequently defined as 16 million colours) at 100 dpi and bitonal images at 300 dpi that is good enough for OCR. If we have an image of 10 x 8 inches, then we need 1000 x 800 dots to express it digitally so that we use 800,000 dots or pixels for the whole image. For 16 million colours we need 3 bytes per pixel; therefore, our scanned image will have 3 x 800,000 bytes = 2,400,000 bytes = 2.4 MB. Now if we reduce the space resolution from 100 dpi to 80 dpi, which may be quite affordable for some types of images, we will need for the same image 800 x 640 pixels, i.e. 3 x 512,000 bytes = 1.536 MB. Thus it looks that by mere reduction of resolution we have saved 864 KB that is a very substantial saving, but, of course, not everywhere this can be applied in order not to distort the original image in an undesirable manner. If we express in other words what we have done, we see that for the same information we used only 80% of resources to express it. If the original information had fine details, lower quantity of picture elements (pixels) to represent them means reduction of the quality of recorded information. In other words, we compressed reality more with 80 dpi than we did it with 100 dpi. This fact can be easily demonstrated when we enhance a part of the scanned image to look closer at its details.
In the above image, the left side is the engine scanned at 100 dpi, while the right image shows the same engine scanned at 80 dpi that seems to give more contrast.
Here we can see a detail image of a part of the carburettor of the same engine: left side at 100 dpi and right side at 80 dpi. We can discern that thanks to higher space resolution the left image is smoother than the right one, while the right image seems to have more contrast. We can use these characteristics successfully in our work. Reduction of brightness resolution The brightness resolution is more frequently called colour depth of the image. It says how many colours are used to express one pixel. If we imagine one pixel of the image as a square and if we use for this square only 1 bit of information, this square can have only two values, i.e. 0 or 1 that means black or white colours. However, if we want to reproduce colour, we must use more information
for one pixel: for example, 4 bits, 8 bits (1 byte), or 24 bits (3 bytes);
accordingly, we have 4-bit, 8-bit, or 24-bit images. If we count colours
in place of pixels, we obtain the following numbers of colours:
To express reality in a true way we use 24 bits per pixel that gives us more than 16 millions of colours. Per one pixel we need then 3 bytes of information and - as counted more above - for our image it takes 2,4 MB. If we dare to reduce the volume of information per one pixel from 24 bits to 8 bits, we need then 3 times less storage space for our image, i.e. 800 KB. Thus we may save substantial space, but we must test, whether we can afford such a substantial loss of information, because all these of over 16 million colours are recalculated into only 256 colours in a palette that is individual for our image. This can be easily detected on the below photograph that was scanned at 16 million colours. The number of colours was reduced onto 256 and 16 to demonstrate the loss of information. Here we have the original true colour image:
The second image has the reduced number of colours onto 256. The reduction
was optimized to minimize the loss of information (error diffusion method).
We can hardly observe the difference, but if we enhance the same detail from the two images and compare the pixels from the same areas, we will see how the 16 million colours have been recalculated into a palette of 256 colours. This happens, for example, automatically during the conversion of a true colour image (uncompressed BMP or TIFF, TIFF/LZW, JPEG, TGA…) into GIF.
In case that we reduce the number of colours onto only 16, the difference is evident in spite of our trying to minimize the losses of information by application of an appropriate error diffusion method. We can examine pixel by pixel on the same positions to see a rough reduction of information: We may also scan images in shades of grey. If applying this to the images of engines from above the result is as follows: 256 shades of grey at 100 dpi (left) and 80 dpi (right).
In some cases - simple colour objects - we may reduce the number of colours - shades of grey - to only 16 and thus to reduce the volume of storage space needed onto 400 KB (in our sample if applicable). However, in most cases, the loss of information is so high that we do not do it. Here we have the same image in 16 shades of grey at 100 dpi (left) and 80 dpi (right). We can observe the reduction of detail, but the images are still usable.
We can even try to optimize the image for 1-bit using error diffusion methods such as Floyd-Steinberg, Stucki, or Burkes. For some type of usage it can be still applicable, but the reduction of colours onto black-and-white image can have even worse results if we apply an inappropriate colour reduction method. Such an image can be hardly used, but sometimes the choice is very difficult, because the method, which is good for image (error diffusion) to produce the so-called halftones, is very bad for text. On the contrary, the colour reduction method good enough for text (nearest colour reduction) is inappropriate for image.
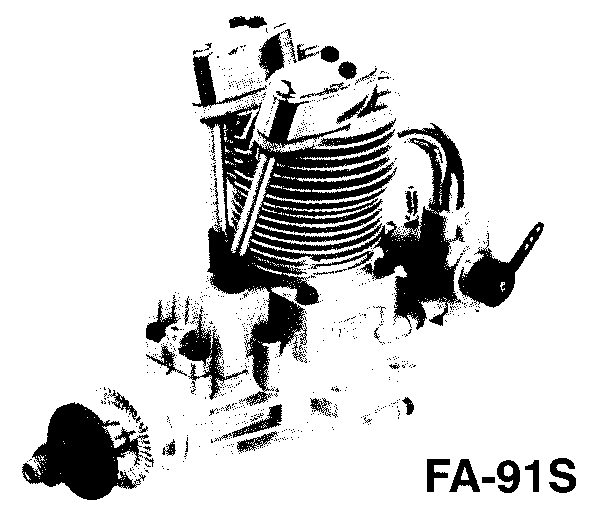
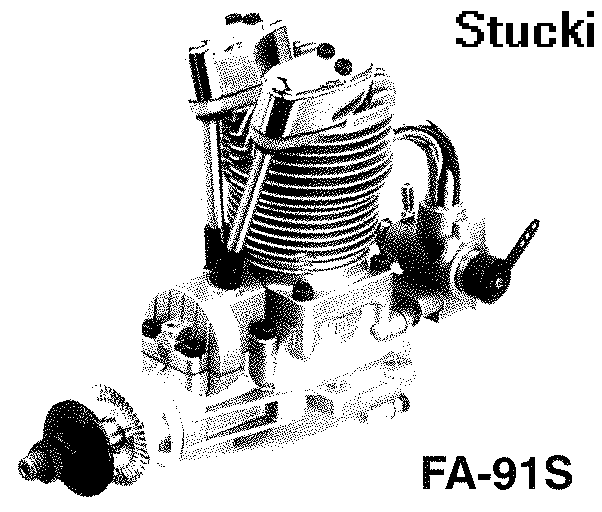
If there is also text with images, we need to apply rather the latter method to be able to enable OCR or to reduce the volume of data files especially when applying lossy compression schemes as, for example, JB2 from DjVu. We can see in the picture below a lot of noise and flipped pixels at the left side, where the black-and-white text has been produced by application of the Floyd-Steinberg error diffusion method, while at the right side it was produced by the nearest colour reduction method. The text is taken from a sample page A4 scanned at 300 dpi. Of course, other error diffusion methods can give other results: in this case, the Stucki error diffusion method produced less noise (see attachments).
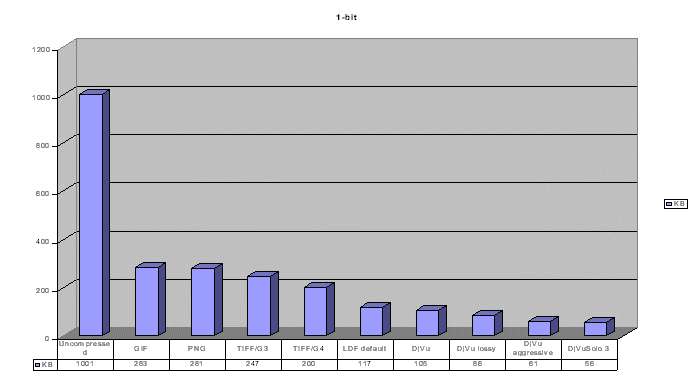
It is also interesting to observe that the size of the uncompressed 1-bit sample file from the beginning of this study will have only 100 KB - comp. with 2.4 MB of the true colour image. This fact is worth to be considered seriously when scanning.
As we can see, sometimes, it is reasonable to refuse colours and to digitize in shades of grey: usually it means to create a palette of 256 shades of grey that is a direct consequence of conversion of the true-colour (24-bit) image into shades of grey (8-bit). It is interesting to realize that even through such a conversion we reduce the size of the image file three times. We may also reduce the number of shades of grey in some cases onto 16. This does not seem to be so disturbing as in case of a palette consisting of only sixteen colours. This may be perhaps explained by the fact that we have been used to read bad quality newspapers. However, everyone must decide on his or her own risk. In other words, we may reduce the true-colour image into the 256-palette image with application of two different operations:
Compression can be lossless or lossy; data delivery in library services is mostly interested in lossy compression schemes. Traditionally, the development of compression schemes happened in two ways:
Best lossless and lossy standards and their emerging follow-on The best-standardized lossless compression schemes used today are CCITT Fax Group 4 for 1-bit (usually implemented in TIFF) and PNG (usually implemented in PNG format). It is also known that the 1-bit ISO compression scheme called JBIG is better than CCITT Fax Group 4, but unfortunately, it is not used. Final ISO draft for JBIG2 is on the way to be approved, but the question is, whether these schemes will be used in products at affordable price. Simultaneously with JBIG2 initiatives for 1-bit images, JPEG2000 initiatives for colour images are under development. The performance of JBIG2-related encoders is evidently far better even in lossless domain than the performance of CCITT Fax Group 4. The best 1-bit encoders implemented in deliverable products are JB2 developed by AT&T and LDF 1-bit encoder developed by the German Luratech company. Their performance is even more accentuated when enabled also for lossy compression as also demonstrated in our recent study. In the domain of colour image, it seems that lossless wavelet compression
techniques will not outperform PNG with more than 10%; therefore, we can
frequently hear that PNG is a format that has its future well ahead. However,
in the lossy domain, wavelets will replace the best-standardized lossy
compression scheme of today that is DCT (discrete cosine transform) as
known from JPEG.
It is also true that PNG and JPEG DCT compression schemes can be applied in TIFF, but these options are not used. There is almost no accessible software to encode TIFF in such a way - Graphic Workshop Professional by Alchemy Mindworks can do it - as well as there is almost no viewer to work with it. TIFF also admits the LZW compression scheme that we know from GIF, but the efficiency of LZW is inferior face to the PNG scheme. The key problem of any lossy compression is establishment of the quality factor or threshold limit of acceptability of the compressed image for the given purpose. This is always individual and the purpose plays here the very decisive role. The following table sums up the options available in colour reduction
and compression domains. We mention only the most used standards and approaches.
As we can see, the reduction of the colour depth is a mighty tool for the document delivery services. The 8-bit image is usually dominated by the GIF format that uses the LZW compression scheme. However, we can encode such an image also in other formats as, for example, TIFF - using the same LZW compression scheme or the Packbits scheme - or PNG. The smallest files are obtained in PNG. The same can be said about 4-bit image. For 4-bit and 8-bit images lossy compression schemes are not used. The 1-bit image, however, is a special case - see our former study about efficiency of 1-bit compression schemes. The purpose of library services is efficient delivery of highly relevant information with the volume of data as reduced as possible. Readers are interested in scanned pages of documents and these documents usually consist of text and images. It is said that their content is mixed. The problem is that the most efficient compression of text is possible in 1-bit compression schemes, while the rest of information must be delivered in colour or shades of grey. It is evident that if we achieve to compress separately the text and separately the colour from an image, we can probably have better lossy results than with any other techniques. Even if we combine CCITT Fax Group 4 and JPEG (as it is possible, for example, in the MRC format designed by Imagepower Inc.), the result is more efficient than that achieved with JPEG only. It is evident from former tests that the best combination would be a
lossy 1-bit compression scheme combined with a good wavelet compression
solution.
However, how to automate the segmentation of objects into those to be encoded bitonally and those to be encoded in colour. Theoretically, there are two possible approaches:
The segmentation - called here zoning - could be performed automatically
and possibly corrected manually or it can be done only manually. The applicable
segments are text, simple graphics, and image (photograph). When segmented,
the page consists of areas marked as T, G, or P; these areas can be also
nested.
The areas are then encoded separately and merged into one format called here MRC (standing for mixed raster graphics). The user can set up, which compression schemes will be applied for each area type. For 1-bit schemes, the choice can be CCITT Fax Group 4 or JBIG2, for graphics and image JPEG or a wavelet scheme, which was here a proper WI format - now it is JPC format that is the Imagepower vesion of JPEG2000. The user can also set up the quality parameters of some of these schemes. The text background can be also set up to zero. When testing the format, we encountered a lot of problems due to the complexity of applied areas in more diversified pages. The format worked in case of simpler pages only. The browser plug-in was unable to display the results correctly, while the plug-in for the higher version of the Power Compressor products was still under development. Other horizontally oriented solutions have not been found.
The vertical segmentation tries to split the image into layers situated one above another. The layer in the foreground is compressed bitonally and the remaining layers in colour. Due to the fact that the segmentation is performed automatically, some pixel groups - be they text or not - are taken as foreground to which colour can be added in the second compressed layer. The rest is considered image and it is compressed in true colour. Keeping in view that the character of individual images differs and that not every image looks well when compressed as mixed raster content, authoring tools of today formats have two other options: compress as text or compress as photograph. In these two cases the wavelet or the bitonal compression encoders are disabled. We can see here the difference between the correct use of the mixed raster content format for encoding a photograph and the incorrect use. The left image was encoded correctly, because it was not segmented into layers and it was encoded entirely as a background image (only true colour wavelet encoding). On the other side, the right image was not encoded by a method that
was appropriate for it. It was compressed as text and image, i.e. segmented
into 1-bit and true colour areas.
The left image is one image in one, but the right image can be split into foreground, coloured foreground, and background image. The segmentation looks like this:
In this explanation, the LuraDocument format was used to demonstrate the character of the mixed raster content encoding. Another used format for this type of encoding is DjVu, it works on the same principles, but the encoding schemes differ. When the LuraDocument uses for 1-bit encoding its own 1-bit encoding
scheme (TIFF G4 option is also possible), DjVu uses its own JB2 encoding
scheme that has a different performance. When for image in LuraDocument
the LWF (LuraWave) format is used, in DjVu it is the IW44 format.
The situation of these two formats is quite interesting, because our former tests have shown that as to 1-bit encoders the DjVu JB2 is better than the LDF 1-bit encoder, but LWF on the other hand is better than IW44. However the word 'better' in case of 1-bit encoders means smaller JB2 files of high quality, while the same word in case of the true image means the better LWF image quality at the same size. It is evident from here that if LDF wants to match DjVu, it must reduce the image background size and quality. This may be a problem, because the quality difference between IW44 and LWF does not play so important role in mixed raster content delivery as it does play in true image representation (representation of photorealistic images). The user expects reduced quality in case if mixed raster content or he can admit it. However, in the case of true image, he requires and expects to receive better quality, because the role of the image in mixed raster content is to illustrate the text, while in the case of true image, the image represents itself. When IW44 scheme segments the image into four sub-layers, LWF apparently uses other techniques, because it is faster at encoding as well as at decoding (display). At larger images of more than ca. 50 MB uncompressed image, the freely available encoding tools LuraDocument Capture and DjVu Shop work differently. When the DjVu Shop is unable to encode such large images on less powerful computers, the LuraDocument Capture has no problems and it is relatively fast. This was the situation with 64 MB RAM, but when upgraded onto 128 MB or more, the DjVu Shop proved a good reliability and acceptable speed. The LuraDocument Command Line Tool is even faster and our tests have shown that the DjVu Command Line Encoder on a Linux machine is also very fast. However, which of these tools offers the best compression? For the moment
being, we know that for 1-bit images it is DjVu and for true colour images
LDF. These results remain outside of the mixed raster content encoding
area, but they can help us when we start to decide, which modern tools
to use for our data delivery. In this sense, it can be also interesting that the Luratech Company has recently implemented JPEG2000 into LWF, version
3.0, into their special JPEG2000 programme. Together with the Image Power Inc. they seem to be the first companies, which have started to develop
deliverable tools with JPEG2000.
Testing a mixed raster content page delivery It is evident that the efficiency of the mixed raster content compression
and delivery will depend on the segmentation of the image. To discover
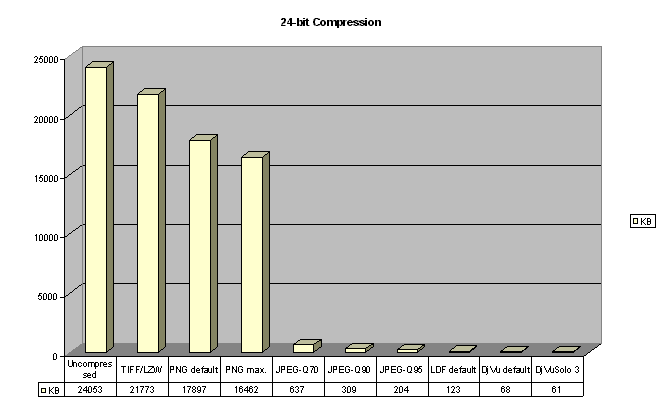
this, we scanned a page from a journal with text and colour images at 300
dpi that resulted into a 24,053 KB uncompressed image.
We used the default values of the encoders, which were DjVu Shop, version 2, for the DjVu format and LuraDocument Capture, version 1.1, both free tools for non-commercial use. The default values for the DjVu tool were 300 dpi for text and 100 dpi for image, while the text background was compressed with the low resolution of 25 dpi; the image background quality factor was set up to 75 and the text was compressed by the lossy scheme. The DjVu output file had the size of 68.1 KB. When the text was compressed as lossless mask, the resulted DjVu file was 81.4 KB. We also tried to apply the aggressive mask for text, but there was no further gain in the final file size compared to the lossy scheme - perhaps only several bytes that was not so important. When we set up the text background mask to 100 dpi, then the final DjVu file size was 90.7 KB. We also combined the set-up in the manner as follows: 300-dpi mask for
text and lossless compression, 100 dpi for text background, and 100 dpi
for image background. In this case the final size of the DjVu file was
104 KB.
The default values for the LDF tool were 'catalogue medium' as to image quality and 300 dpi, while the bitonal encoder was LDF 1-bit encoder. The obtained LDF file had 160.5 KB. When we set up the LDF tool to 'catalogue low' - this referred to the background image - then the LDF output file was 123 KB. We also used the LuraDocument Command Line Tool whose testing was enabled for us by the Luratech Comp. and we tried to combine encoding masks of various resolution values separately for text and image. When we used 300 dpi for text and 100 dpi for background image, the final size of the LDF file was 99 KB, but the quality of the encoded image was rather poor. Another possibility was to omit the text background layer and to encode the text bitonally and the image in LWF. The final size of the LDF file was then 80 KB, but there was loss of that information, which we did preserve in DjVu; therefore this result could not be used for comparison. Finally we took the CCITT Fax Group 4 scheme for text in place of the
LDF encoder. The final size of the LDF image grew with 34 KB, i.e. 152.87
KB (G4 and medium LWF quality), while for LDF 1-bit and low LWF quality it was 121.84 KB.
We tried also other settings for the resolution of both masks, but we were
unable to create smaller files with acceptable readability or understandability
especially for graphics.
We can sum up the results into the following table:
As we can see, the LDF files are larger, the lowest difference being
ca. 30 KB, but in this case the LDF file had a very bad image quality and
it was not comparable to the 68.1 KB DjVu file. On the other hand, the
default output images of 68.1 KB for DjVu and 123 KB for LDF were well
comparable; it can be said that they were equal as to their quality when
evaluated from the user's point of view. Of course, they were not identical
as to various textual and image artifacts and the quality of representation
of certain elements of the scanned page, but they could play the same quality
role in the delivery services.
As demonstrated on the comparison of both DjVu and LDF segments (see attached Comparison of DjVu and LDF layers), it is evident that here the LDF 1-bit segment carries more information than the JB2 segment. This situation does not change if we add the text background to have the whole coloured foreground. On the other hand, the LDF image (LWF format) background is more or less another text background, while the DjVu image (IW44 format) can be considered as a certain kind of blurred image. In general, the LDF and DjVu formats are quite comparable as to size in the background image representation, where the quality aspect would be slightly in favour of LDF (LWF). However, LDF stores here fewer data in the background image segment than in the foreground image segment, while DjVu does it on the contrary. If LDF managed to store the same or comparable segments of data in the same layers as DjVu, DjVu would outperform LDF only in the 1-bit domain thanks to the demonstrated quality of JB2 and the difference in size of LDF and DjVu files would not be so big. Unfortunately, LDF stores substantially more information in 1-bit layer than DjVu; therefore, the sizes of the output files are so different: DjVu outperforms (in the case of our page) LDF twice. Apparently also the resolution of the background image is higher (300 dpi) at LDF than at DjVu (100 dpi). On the other hand, if we reduce the resolution of the background image at LDF down to 100 dpi (Command Line Tool), we are almost losing the image. Maybe if LDF would try to store more information in the background image than it does now, it would not need to store so much data in the 1-bit layer, where its performance is not so good. Perhaps thus the difference between DjVu and LDF would not be so acute as it is now. To achieve this more balanced situation, the vertical segmentation of LDF should be tuned more in favour of the LWF compression scheme (background) than in favour of the 1-bit scheme as it is now. Today, LDF stores less information than DjVu in the segment in which
their performances are comparable and it does store more information in
the foreground segment, where it is not so efficient, because DjVu/JB2
outperforms the LDF 1-bit encoder substantially (see our former tests).
Wider comparisons with traditional approaches If we take the problem from a very practical point of view, we can compare the efficiency of reduction of the colour depth and application of various lossless and lossy compression schemes. All figures in graphs are given in KB. True colour - 24-bit image- 16,7 million colours Our test image of more than 24 MB was scanned from a colour journal at 300 dpi and compressed as true colour image with various lossless and lossy compression schemes with the following results:
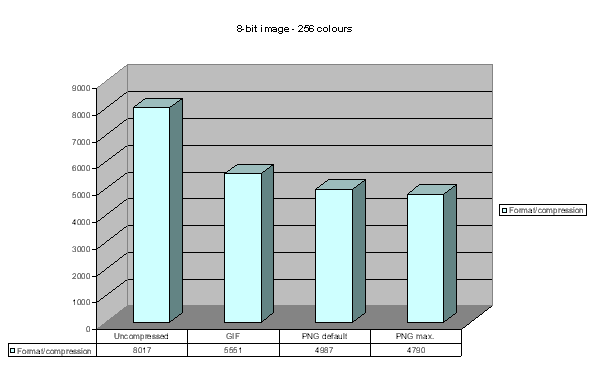
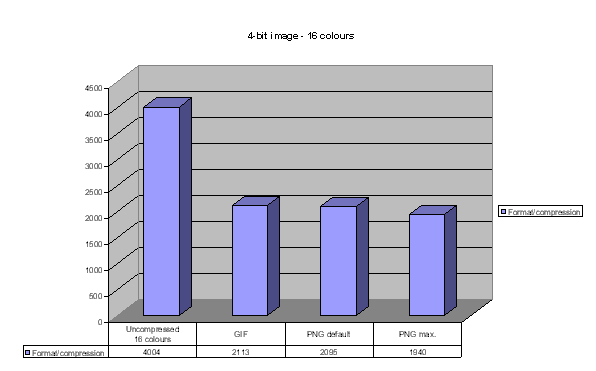
Further reduction of colour depth
The colour depth of the test image was reduced onto 256 colours and after it onto 16 colours. These two images were compressed in GIF and PNG. In both 256 and 16-colour domains, the PNG format was more efficient than GIF, but the files remained rather large: 4790 and 1940 KB. It is evident that the lossy true colour JPEG is a better solution than reduction of the colour depth.
We reduced the number of colours onto black and white only and compressed this image with several lossless and lossy methods. The importance of TIFF/G4 was confirmed as well as very good results of LDF and DjVu/JB2. In the lossy domain, DjVu/JB2 was able to compress the file down onto 61 KB, while the DjVu 3 onto 56 KB only. The 1-bit source image was obtained through dithering with the nearest colour reduction method so that it may be said that all the obtained images are very suitable for OCR processing.
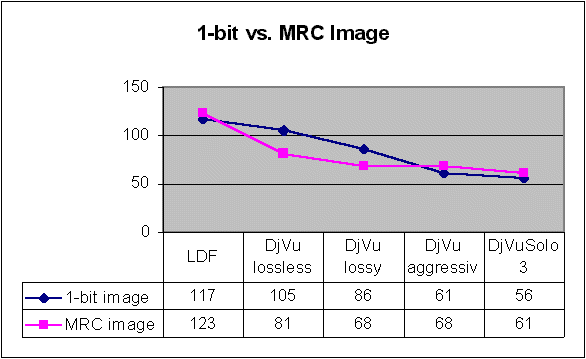
It is evident that for document delivery the best solution is the true colour mixed raster content approach. Thanks to this, the user has access to good quality colour information and well readable text. The difference between the best 1-bit compression performance and the best mixed raster content performance is very small. For LDF it is only 6 KB (117 KB vs. 123 KB) and for DjVu only 7 KB (61 KB vs. 68 KB).
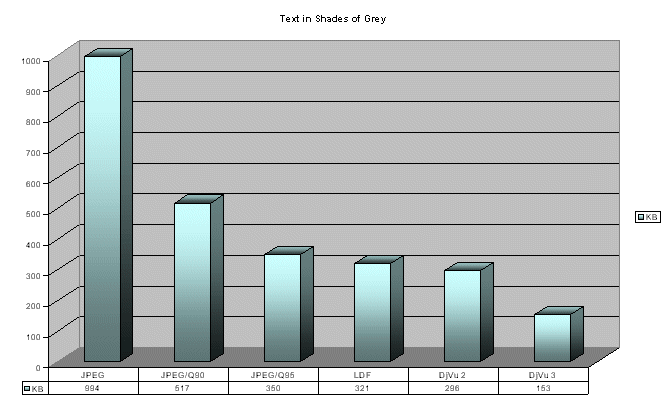
However, within the most used DjVu MRC settings such lossy 1-bit compression - that is default - and lossless 1-bit compression, the size of the MRC image is smaller than that of the corresponding 1-bit image. This fact is rather interesting and it is due to optimized segmentation of layers and their distribution to 1-bit and colour compression areas. As it can be seen from the attached samples, the wavelet compression takes a part of data from the traditional 1-bit area compared with the pure black-and-white dithering procedures. This was also possible thanks to the fact that the compressed original page was composed from about 50% of text and 50% of images. Textual document in shades of grey However, in our digitization programme, acid-paper materials must be frequently scanned in grey scale, because the condition of the original is so poor that through dithering onto 1-bit image the readability of the text can be seriously endangered. To test the compression also here, we have taken an image of a typewritten page from the so-called Russian Historical Archives Abroad. The JPEG image in 256 shades of grey has 994 KB - face to the uncompressed image of ca. 22 MB - while the JPEG with the Quality Factor 90 has 517 KB and that with the Factor 95 has 350 KB. The text has remained well readable, but the background is full of artefacts caused by the tough compression. The LuraDocument file - LuraDocument Capture software with the low quality
background - has produced a file sized 321 KB; the result was excellent.
We have also tried to dither the image onto 1-bit and to compress it afterwards.
We have thus obtained a TIFF image compressed with CCITT Fax Group 4; it
has the size of 184 KB. We have been able to compress it down with LDF
onto 134 KB, with DjVu 2 onto 90 KB, and with DjVu 3 onto 87 KB. We have
also tried to compress and to dither the image with DjVu directly from
JPEG: the resulted file is slightly larger in this case - 117 KB.
Also in this case, we have observed that a part of the text layer has moved in the MRC scheme into the wavelet compression background segments. In DjVu 3, the 1-bit file has 87 KB, but the 1-bit layer in the MRC solution has only 80 KB.
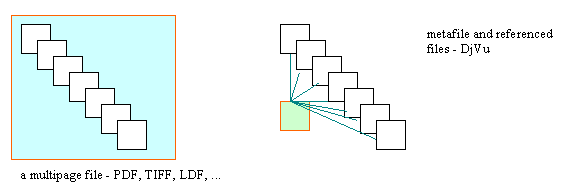
It is evident also that the methods for simple dithering try to preserve the maximum of information in the black-and-white representation. The mixed raster content approach places, however, only a part of it into the 1-bit text layer, while all the rest is encoded in wavelets and very efficiently. The new version 3 of the DjVu format as tested in the DjVuSolo program enables a very efficient compression, but it is much more computation intensive than the former version. The DjVuSolo program also requires display of the source image and only after this it is possible to convert it, while the DjVuShop loaded the source image through conversion. The new program offers also less opportunities to set up the compression ratios than the old one does. It has been designed for practical use and as such it seems to copy the philosophy of the LuraDocument Capture. However, the LuraDocument Capture program is very fast, while the Windows DjVu encoding tools are slow on less powerful computers. They require more memory and better processor performance. However, the professional command line tools on the Linux platform are substantially faster and also the variety of possible settings is very rich. The results of the DjVu encoding are astonishing; therefore, we have decided to apply them in our digital library. There are a lot of opportunities for delivery of scanned materials over networks. The word 'delivery' supposes existence of a contract or some basic understanding between the service provider and its user. If this contract enables reduction of data down to the limit of acceptable readability and understanding, then we can apply the mixed raster content (MRC) delivery concept. However, we must be aware of the fact that MRC formats have a lot of parameters and that we must know their properties to be able to apply them correctly. There is always difference between a page of a journal with text and images, a page from a manuscript or a photograph, or a simple black text on white paper. All of them can be delivered by DjVu or LDF, but not onto all of them the MRC philosophy can be applied. The MRC formats are an opportunity of application of two different compression schemes onto the same image. They give us also the liberty to switch off one of the compression schemes and to use that, which remains. In these cases - when one of the compression schemes is switched off - they behave as very efficient - the most efficient ones of today - formats for 1-bit or colour encoding. They outperform traditional 1-bit and photorealistic compression solutions. Furthermore, they are even much better when we allow them to apply both compression schemes in one image. It is evident from the tests that if we want to economize storage space and to reduce the network traffic, DjVu is a better solution than LDF. On the other hand, it should be said that both solutions are on the market and that they are better than any third solution that may be applied. If we work with free tools, we have comparable viewing plug-ins for the two most used web browsers and we have two Windows tools to encode the files. When the files get larger, we will appreciate the speed of the LDF tool on less powerful machines. When moving towards encoding of larger files, the DjVu Shop requires more memory. However, when viewing the files in web browsers, the DjVu plug-in seems to be faster and to offer more comfort. Its speed is also partly given by the characteristics of the DjVu image for the first display of which only a part of data is needed. Both formats enable storage of more images (scanned pages) in one file. The free LDF tool enables creation of up to eight images in one file and the license to open the limits of this functions costs only ca. 30 USD.
If we want to do the same with DjVu, we can use the DjVuSolo program and, of course, commercial tools or special free command line tools for creation of multi-image files that may be very difficult for common users. On the other hand, the DjVu philosophy and the free command line tool for grouping individual DjVu files enable virtual - not physical - merging of separate files into one. The advantage of this solution is that only the page requested during browsing by the user is transferred over networks; not all the files or pages as it happens in case of LDF, PDF, or multipage TIFF.
On the left image all the individual files are transferred in one file. This method is used in PDF, LDF, and TIFF. We have this option in DjVu, too. However, in case of DjVu, the total size of individual 1-bit layers grouped in one file is smaller than the total size of these 1-bit layers remained in individual files ungrouped. This is due to use of the common shared dictionary for all the pixel groups gathered in the former case, while in the latter case several individual dictionaries are used. On the right image, we receive - when clicking on the name of the metafile - only this very slim metafile and the first page. When we follow to browse the document, we receive only that file, which we require: it may be the previous file or the next file, but also any other file referenced. We only indicate in the plug-in menu, which number we want. If we want to use LDF or DjVu in high volume, even in some document delivery application in the digital library, we will need the so-called command line tools, which are very fast. The LDF command line tool costs almost 3000 USD, while the DjVu command line tool for mixed raster content costs 7000 USD. This fact can be also important when taking our decision, which of them we should use. Another important factor is that, which input formats for conversion are applicable. The Windows tools accept JPEG, while the command line tools - in case of LDF - not, while the DjVu command line encoder does accept it. LDF command line tool accepts uncompressed bitmaps as TIFF, BMP, or RAS. It is evident that JPEG input is important for some segment of use. This is true especially when we convert existing files and do not scan only for delivery, because in this case it is rather probable that storage of true colour image is done rather in JPEG than in some uncompressed format. --------------------
The following samples are available via Internet:
Adolf Knoll is deputy director of the National Library of the Czech Republic, responsible for strategic planning, research, and technology development. Since 1993, he has been active in development of co-operation with the UNESCO Memory of the World programme; today he guarantees the national programmes Memoriae Mundi Series Bohemica as a programme of digital access to rare documents and the Digital Library programme as an archive for the digital documents produced by Czech libraries. In 1990s, he was active also in various other initiatives launched by the European Commission and UNESCO. In 1997-2000, he was member of the International Advisory Committee of the Memory of the World programme and since 1996 he has been member of its Sub-Committee on Technology.
|

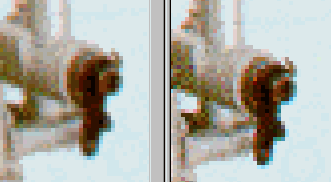
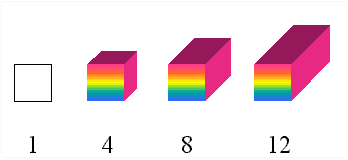





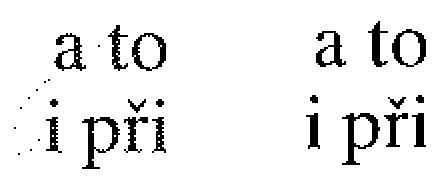


 If we
take a page from a modern journal, we can observe that there is text and
that there are images and simple graphics; moreover, there is also coloured
background or images used as background. The idea of horizontal segmentation
was demonstrated by Power Compressor by Imagepower Inc.
If we
take a page from a modern journal, we can observe that there is text and
that there are images and simple graphics; moreover, there is also coloured
background or images used as background. The idea of horizontal segmentation
was demonstrated by Power Compressor by Imagepower Inc.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}